
A Detailed Guide To Use Amazon Scraper
Web scraping Amazon can be highly lucrative for businesses if done smartly. Don’t believe us? Consider this story of a website that made a jaw-dropping $800k within just two months while all they did was scrape Amazon reviews daily. Cool, huh?
We can't promise you'll make a ton of money overnight, but we can teach you how to scrape Amazon to try and get there.
So read this blog to learn two ways to scrape Amazon: one using a no-code Amazon Scraper and another where we build a Python Amazon Scraper through code.
But first, let's find out if it's okay to scrape Amazon.
Is It Legal To Scrape Amazon?
When it comes to scraping Amazon, the rules are a bit fuzzy. Amazon's robots.txt file delineates permissible scraping parameters in a long list that specifies what is scrapable and which areas are strictly prohibited.
However, the robots.txt file serves merely as an ethical guideline and isn’t legally binding. So, your Amazon Scraper may access off-limit areas without necessarily facing any issues.
However, Amazon doesn’t stop here. It goes further by implementing technical barriers to prevent bots from overloading its servers.
For instance, it employs anti-scraping measures like CAPTCHA tests and rate limiting. To overcome these obstacles, your Amazon scraper must possess advanced techniques like user agent spoofing, CAPTCHA solving, or delaying requests; otherwise, your Amazon scraping endeavor would remain a dream.
Therefore to briefly answer “Does Amazon allow web scraping?”: the legality of web scraping Amazon data is not clear-cut and depends on various factors including
-
the type of data scraped
-
the methods used for scraping
-
and the purpose of the scraped data
As long as scraping does not involve unauthorized access, e.g., data behind a login, or overwhelm the site's infrastructure, it typically falls within the safe category. The Supreme Court also defended a Data Analytics firm that was sued by LinkedIn under CFAA, citing unauthorized web scraping.
Moreover, you should also ensure that your use of scraped data is legal, i.e., you do not resell or replicate it as that can have serious legal repercussions.
Now the million-dollar question, how to scrape Amazon?
How To Scrape Amazon?
Despite technical challenges, it's easy to scrape Amazon. There are many code and no-code tools on Amazon scraping with solutions for tackling Amazon’s anti-bot measures. You can easily scrape Amazon reviews, products, and prices among other data using these tools.
So let’s begin with the no-code Amazon Scraper first.
No-Code Amazon Scraper:
Let's be honest, odds are high that the current reader reading this doesn’t have coding skills. But that’s no issue. You don’t need coding knowledge when no-code Amazon Scrapers are available.
With these tools, you just provide the product or category page URLs and the scraper will get you all Amazon product data from that page. When they are done with web scraping Amazon you are also provided with multiple file-saving options.
We have chosen Apify’s Amazon Scraper for this demo. Apify has separate tools for scraping different areas of Amazon including Amazon Product Scraper, Amazon Review Scraper, and Amazon Bestsellers Scraper.
In this guide, we’ll be using Apify’s Amazon Product Scraper. The Amazon Product Scraper has features to solve CAPTCHAs and set proxies to help evade anti-bot measures.
So let's start the demo.
Step 1: Visit the Amazon Product Scraper Page
Access the Amazon Product Scraper on the Apify Store and hit the ‘Try for Free’ button. This tool lets you scrape Amazon product data including prices, reviews, product descriptions, images, and several more attributes.
Step 2: Create Your Apify Account
If you're new, sign up for an Apify account for free. The platform offers sign-up options via email, Google, or GitHub. 
Step 3: Paste Amazon URLs Of Target Content
In the Apify Console, input the URL of the Amazon product or category you wish to scrape. We have used the Video Game Consoles & Accessories and the Furniture category in this example.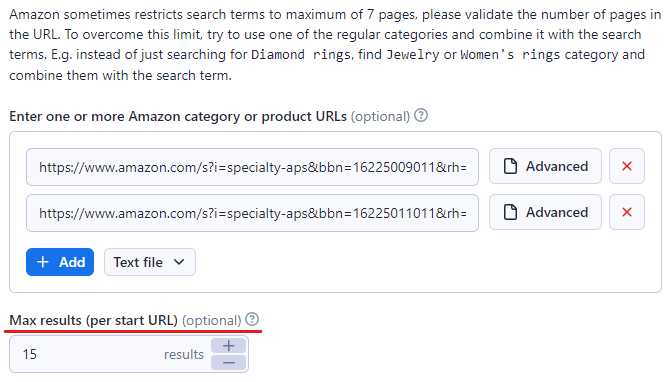
You can insert more links by pressing the ‘+ Add’ button. Or if there are many links, you can just add them all to a text file and upload it to the Amazon Scraper.
Also, decide on the maximum number of items you aim to scrape by setting a limit in the 'Max items' field. We have set it to 15 but you can set it as high as you wish.
Step 4: Enable the CAPTCHA Solver
You cannot scrape Amazon without a CAPTCHA solver. Amazon is known to be very efficient at detecting bots. As soon as it suspects bot activity it throws a CAPTCHA at the bot.
So to make sure your Amazon Scraper operates hassle-free, enable CAPTCHA solving.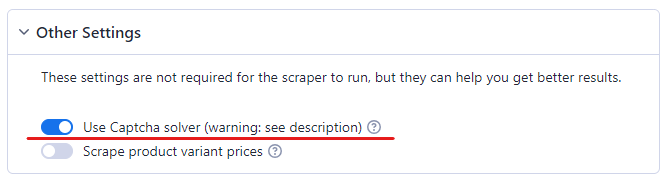
Step 5: Configure Proxy
Employing a proxy is essential for bypassing anti-scraping measures. The Amazon scraper offers various proxy options, including Residential, Datacenter, or your own, to mask scraping activities and navigate around restrictions. Read about the differences between Residential and Datacenter proxies in our other blog.
The residential proxy option is selected by default as it is the best for anti-scraping systems.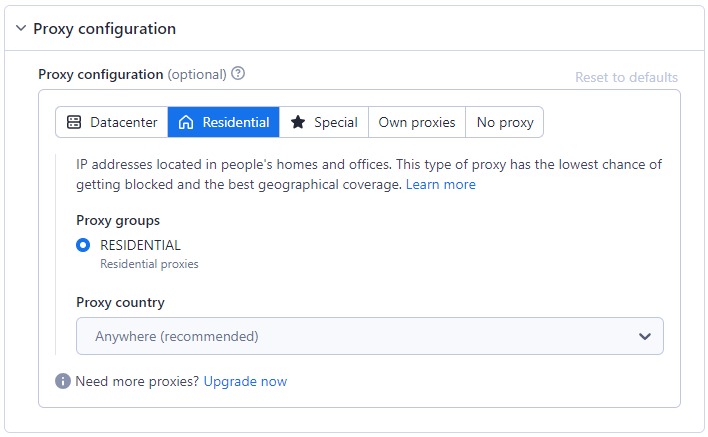
Step 6: Launch the Scraper
With your parameters set, start the Amazon Product Scraper by pressing the ‘Start’ button at the bottom of the page.
The status will change from 'Running' to 'Succeeded' upon completion.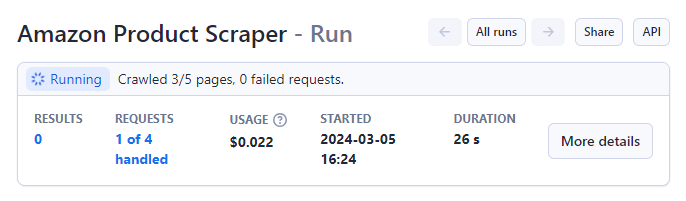
After completion, you’ll see the preview of the data on your screen.
Step 7: Export Your File
Press the 'Export results' button to download your collected data. The platform supports multiple formats, including CSV, JSON, and Excel.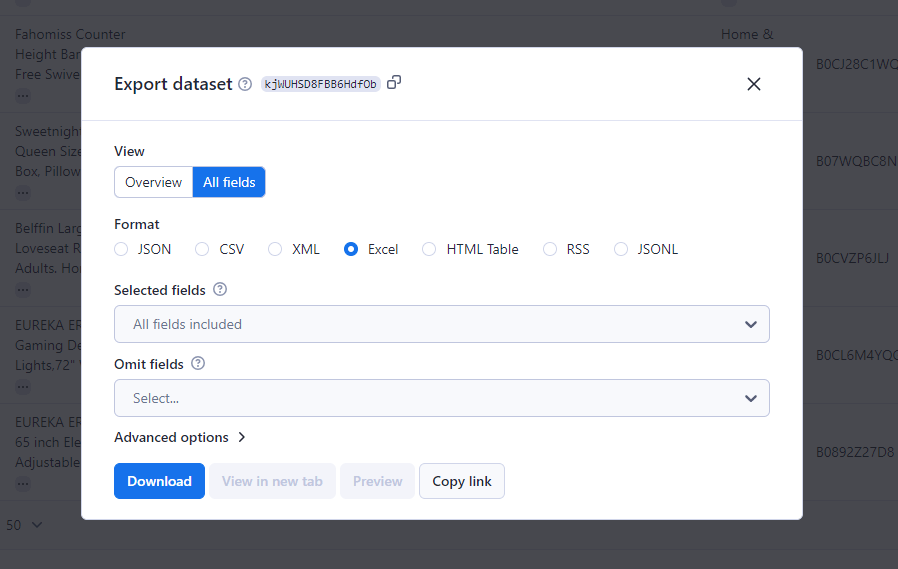
Python Amazon Scraper Using Programming
In the no-code Amazon Scraper we used above, if you look closely at the previously mentioned step 6, 69 out of 173 requests failed. This is because Amazon is blocking those requests.
To bypass this issue you’ll have to program your own scraping script. In this guide, we are making a Python Amazon Product Scraper.
So let's begin.
Step 1: Install Python
To code our Python Amazon scraper, it's essential to have Python installed on your computer. It’s recommended to download the latest or recent versions for compatibility with the required libraries.
Step 2: Importing Necessary Libraries
The crux of any Amazon scraper involves fetching and parsing web content. For this, we use a combination of Python libraries.
-
Requests: for making HTTP requests to Amazon's website
-
BeautifulSoup: To navigate and parse the HTML content returned
-
lxml: for parsing
-
Pandas: for organizing and exporting data
Before importing them you’ll have to install them using the following command:
Now we’ll import them inside our Amazon scraper Python script:
Step 3: Configuring HTTP Headers
A common hurdle in Amazon web scraping is Amazon's defensive measures against automated access. To avoid this, our Amazon scraper Python script mimics a web browser's request by including custom HTTP headers, such as 'User-Agent' and 'Accept-Language'.
It’s a better practice to add more headers.
To get these headers for your browser,
-
press F12 on an Amazon page to open developers tools,
-
Open the Networks tab and Select Headers
-
Reload the page
-
Select the first request
-
In the Headers tab, scroll down to Request Headers section and copy the values of headers mentioned above
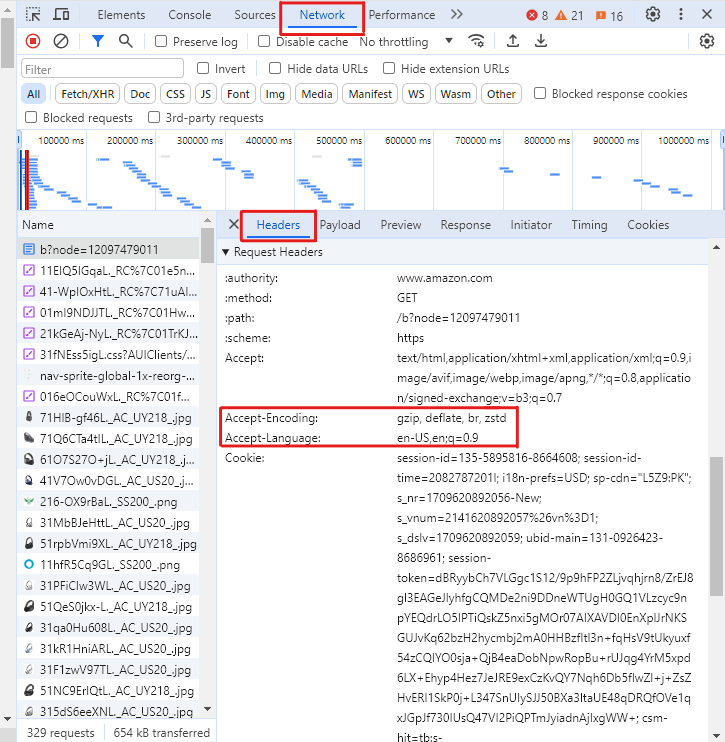
Without these headers, there are high chances that Amazon may block the get requests and return a response like the following with a status_code 503 (error) instead of 200 (success).
Step 4: Extracting Product Information
Our Amazon Product Scraper includes the function scrape_amazon_product which performs the critical task of extracting product details. The function takes the the Amazon category page URL as an input and returns a dictionary with the product’s info.
The method then sends a request to Amazon using the URL and the custom headers variable we created above.
After that, using BeautifulSoup's CSS selectors, we will retrieve the product's title, price, image URL, and description from individual product pages.
Step 5: Dealing With Product Listings & Pagination
For our Amazon scraper Python script to collect extensive data by moving through category pages and handling pagination, the script navigates through Amazon's product listing pages.
It identifies product links using CSS selectors and follows pagination by detecting the 'Next' page link.
Step 6: Saving Scraped Data
Finally, the scraped data is aggregated into a list of dictionaries, which is then converted into a Pandas DataFrame. This DataFrame is then exported as a CSV file.
Use Amazon Scraper Stealthily
Scraping Amazon is usually straightforward. However, you might face multiple challenges like CAPTCHAs, request blocks, and rate limits.
To avoid bumping into these issues, you should use an anti-detect browser like AdsPower. AdsPower makes sure your Amazon scraper remains undetected by offering features like fingerprint spoofing and proxy rotations.
So sign up for free now and start scraping Amazon seamlessly.
