
5 Maneiras Eficazes de Realizar Web Scraping Sem Ser Bloqueado

Você sabia que cerca de 47% de todo o tráfego da internet é gerado por bots, incluindo scrapers web? Em um mundo digital onde os dados são tudo, vasculhar a web em busca de informações se tornou uma necessidade para muitas empresas.
No entanto, por mais essencial que seja esse processo, ele vem com seus desafios, desde CAPTCHAs que bloqueiam o acesso automatizado até armadilhas de honeypot que atraem e expõem bots.
Mas nosso foco principal não está nesses obstáculos. Estamos aqui para explorar soluções eficazes para contorná-los e permitir o scraping suave da web sem ser bloqueado.
Este artigo descreve cinco maneiras de realizar o scraping da web com sucesso sem ser bloqueado. Desde o uso de um navegador anti-detecção sofisticado até o agendamento de suas tarefas de scraping durante horários menos movimentados, abordamos diversas técnicas.
Ao implantar esses métodos, você não apenas reduzirá as chances de ser bloqueado, mas também melhorará a eficiência e a escala de suas atividades de scraping na web.
Vamos mergulhar e ajudá-lo a coletar dados importantes sem nenhum obstáculo.
Desafios no Web Scraping
Os riscos e desafios da extração de dados variam de barreiras técnicas a armadilhas deliberadamente configuradas por sites. Compreender esses desafios é um passo fundamental para desenvolver uma estratégia sólida de web scraping.
A seguir, destacamos alguns dos desafios mais comuns enfrentados pelos scrapers.
5 Maneiras de Fazer Web Scraping Sem Ser Bloqueado

Embora o web scraping apresente diversos desafios, cada um deles possui soluções que facilitam a coleta de dados sem bloqueios. Vamos explorar essas técnicas e compreender como elas podem ser utilizadas para realizar web scraping de maneira eficiente.
Navegador Headless
Uma técnica eficaz para realizar web scraping sem ser bloqueado é o chamado headless browsing. Essa abordagem envolve a utilização de um navegador headless, um tipo de navegador sem interface gráfica do usuário (GUI).
Um navegador headless pode simular a atividade de navegação de um usuário típico, ajudando você a permanecer indetectável por sites que usam Javascript para rastrear e bloquear web scrapers.
Esses navegadores são particularmente úteis quando o site alvo está carregado com elementos Javascript, já que os scrapers HTML tradicionais não possuem a capacidade de renderizar tais sites como um usuário real.
Navegadores populares como Chrome e Firefox possuem modos headless, mas você ainda precisará ajustar seu comportamento para parecer autêntico. Além disso, é possível adicionar outra camada de proteção combinando navegadores headless com proxies para ocultar seu IP e prevenir banimentos.
Você pode controlar programaticamente o Chrome headless através do Puppeteer, que fornece uma API de alto nível para navegar em sites e realizar praticamente qualquer ação neles.
Por exemplo, segue um script Puppeteer simples para criar uma instância de navegador, capturar uma imagem de uma página da web e, em seguida, fechar a instância:
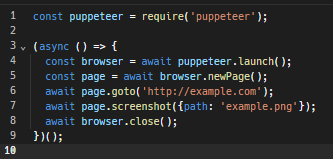
Tutorial detalhado de Headless Browsing com Puppeteer
Scrape durante horas de baixa atividade
O web scraping envolve a navegação em sites em um ritmo muito rápido, um comportamento incomum entre usuários comuns. Isso pode levar a altas cargas de servidor e lentidão de serviço para outras pessoas. Como resultado, os administradores do site podem perceber o scraper e expulsá-lo do servidor.
Portanto, uma jogada inteligente para fazer web scraping sem ser bloqueado é realizá-lo durante os horários de baixa atividade do site. É quando os sites geralmente estão menos protegidos. E, mesmo que suas atividades de scraping consumam muitos recursos do servidor, pode não ser suficiente para esgotá-lo e chamar a atenção dos administradores.
No entanto, ainda há uma chance de ser pego. Alguns sites podem ter medidas sofisticadas para monitorar a atividade do usuário, mesmo durante períodos de menor movimento. Além disso, determinar os horários de baixa atividade de um site pode ser complicado se as informações disponíveis não estiverem atualizadas.
Use um Navegador Antidetect
Um navegador antidetect é uma ferramenta completa projetada para manter os usuários anônimos e ocultar suas atividades online dos sites que visitam. Ele funciona mascarando ou alterando a impressão digital do navegador do usuário, que normalmente é composta por detalhes como tipo de navegador, plugins, resolução de tela e fuso horário, todos usados pelos sites para rastrear as atividades do usuário.
Isso torna os navegadores antidetect ideais para fazer web scraping sem ser bloqueado. No entanto, é importante notar que esses navegadores apenas reduzem os riscos de detecção, não são completamente infalíveis contra todos os sites. Portanto, escolher o melhor navegador antidetect para web scraping é crucial para minimizar as chances de ser detectado.
Um bom navegador antidetect para web scraping é o AdsPower. Ele usa técnicas específicas para evadir medidas anti-scraping, como:
Além dos recursos mencionados, o AdsPower também oferece benefícios adicionais, como automação de scraping e vários perfis de navegador para agilizar o processo de scraping.
Resolvendo CAPTCHAS Automaticamente ou Usando Serviços Pagos
Para evitar CAPTCHAs durante o scraping da web sem ser bloqueado, você tem várias opções. Primeiro, considere se pode obter as informações necessárias sem acessar seções protegidas por CAPTCHA, pois codificar uma solução direta é um desafio.
No entanto, se o acesso a essas seções for crucial, você pode usar serviços de resolução de CAPTCHAs. Esses serviços, como 2Captcha e Anti-Captcha, empregam pessoas reais para resolver CAPTCHAs por uma taxa por teste resolvido. Mas lembre-se que depender apenas desses serviços pode prejudicar seu orçamento.
Alternativamente, ferramentas dedicadas de scraping de web, como o ZenRows' Data Collector e a ferramenta de rastreamento de dados da Oxylabs, podem ignorar automaticamente os CAPTCHAs. Essas ferramentas usam algoritmos avançados de aprendizado de máquina para resolver CAPTCHAs e garantir que suas atividades de scraping continuem sem problemas.
Armadilhas de Honeypot
Para lidar eficazmente com armadilhas de Honeypot no web scraping sem ser bloqueado, é fundamental reconhecê-las e evitá-las. As armadilhas de Honeypot são mecanismos projetados para atrair e identificar bots, muitas vezes se apresentando como links invisíveis no código HTML de um site, ocultos às pessoas, mas detectáveis por scrapers.
Uma estratégia é programar seu rastreador ou scraper para identificar links que são invisíveis para usuários humanos por meio de propriedades CSS. Por exemplo, evite seguir links de texto que se misturam à cor de fundo, pois essa é uma tática para ocultar deliberadamente links dos olhos humanos.
Aqui está uma função JavaScript básica para detectar esses links invisíveis:
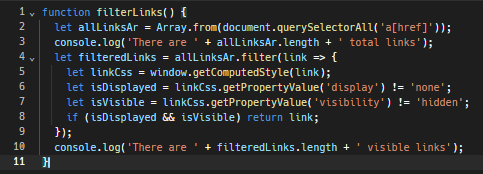
Além disso, respeitar o arquivo robots.txt do site é crucial. Este arquivo é destinado a bots e estabelece o que pode e o que não pode ser feito no scraping. Ele oferece informações sobre as áreas do site que estão fora dos limites e as partes onde o scraping é permitido. Seguir essas regras é uma boa prática e pode ajudá-lo a evitar armadilhas de honeypot.
Concluindo!
Claro, existem medidas anti-scraping que nos impedem de acessar dados valiosos em sites de destino e às vezes até nos banem permanentemente. Mas nenhum desses desafios é impossível de superar.
Você pode usar ferramentas como navegadores headless para imitar a navegação real, fazer scraping durante horários menos movimentados para evitar detecção, e usar navegadores anti-detecção como AdsPower para ocultar suas impressões digitais. Além disso, também existem maneiras de contornar CAPTCHAs e evitar honeypots.
Com essas táticas, o web scraping bem sucedido sem ser bloqueado é facilmente alcançável. Portanto, vamos deixar para trás a abordagem de tentativa e erro e começar a fazer scraping de maneira inteligente.
As pessoas também leem
- Navegadores Antidetecção para Afiliados: Evite Banimentos e Aumente o ROI
- 10 Melhores Navegadores Anônimos para Navegação Privada e Segura na Web
- Top 8 Modelos de Negócios de Afiliados: Como Escolher o Melhor para o Seu Negócio (Guia 2025)
- Os 10 Melhores Navegadores Headless para Web Scraping: Prós e Contras
- Para Iniciantes: Como Obter Airdrops de Criptomoedas em 2025
