
Os 10 Melhores Navegadores Headless para Web Scraping: Prós e Contras
Dê uma olhada rápida
Quer turbinar seu web scraping? Navegadores headless são sua arma secreta. Descubra como eles funcionam, por que são incríveis e quais deles elevarão seu jogo de scraping a outro nível.
Você já precisou extrair grandes quantidades de dados online de forma eficiente, apenas para descobrir que os navegadores tradicionais atrasam seu processo? Desde o rastreamento de preços até a análise competitiva, o web scraping é crucial para automatizar a coleta de dados. No entanto, usar um navegador comum para scraping pode ser lento e ineficiente. Quando a velocidade e a automação são importantes, qual é a melhor solução?
Neste guia, exploraremos os 10 melhores navegadores headless para web scraping, detalhando seus pontos fortes e fracos para ajudá-lo a escolher a ferramenta certa para suas necessidades.
O que é um Navegador Headless?

Em poucas palavras, um navegador headless é um navegador da web sem uma interface gráfica (GUI). Ele opera em segundo plano, buscando e renderizando páginas da web como um navegador comum, mas sem exibi-las na tela. Isso torna os navegadores headless perfeitos para tarefas como web scraping, testes automatizados e monitoramento de desempenho.
A propósito, o modo headless de um navegador antidetecção, como o AdsPower, oferece capacidades semelhantes aos navegadores headless tradicionais, mas com maior discrição. Enquanto os navegadores headless tradicionais costumam ser sinalizados devido à falta de impressões digitais (fingerprints), o modo headless do AdsPower ajuda a evitar a detecção ao mascarar e modificar essas impressões, fazendo com que suas solicitações pareçam vir de usuários legítimos e únicos.
|
Caso de Uso |
Modo Headless do AdsPower |
Navegadores Headless Tradicionais |
|
Gerenciamento de múltiplas contas |
✅ Sim |
❌ Não |
|
Bypass de detecção de bots |
✅ Sim |
❌ Não |
Como Iniciar o AdsPower no Modo Headless?
1. Vá para Configurações de API no AdsPower e clique em Gerar ou Redefinir para obter sua chave de API.

2. Inicie o AdsPower no Modo Headless (abra o CMD ou Terminal no diretório raiz do AdsPower):
- Windows: "AdsPower Global.exe" --headless=true --api-key=XXXX --api-port=50325
- macOS: "/Applications/AdsPower Global.app/Contents/MacOS/AdsPower Global" --args --headless=true --api-key=XXXX --api-port=50325
- Linux: adspower_global --headless=true --api-key=XXX --api-port=50325
3. Verifique o endereço de retorno na linha de comando para confirmar a inicialização bem-sucedida.

Guia Completo: Documentação da API do AdsPower – Modo Headless
Como os Navegadores Headless Diferenciam-se dos Navegadores Tradicionais?
Pense assim: enquanto os navegadores tradicionais são projetados para interação humana — com botões para clicar, páginas para rolar e imagens para admirar — os navegadores headless eliminam os elementos visuais. Eles focam exclusivamente na funcionalidade, permitindo que você interaja programaticamente com sites. Aqui estão algumas diferenças-chave que tornam os navegadores headless particularmente adequados para tarefas de automação:
- Sem GUI: Navegadores headless operam sem exibir a página da web visualmente, o que é benéfico para ambientes de servidor, pois reduz o consumo de recursos computacionais. No entanto, a falta de feedback visual pode tornar a solução de problemas mais desafiadora, já que não há pistas visuais para ajudar no diagnóstico.
- Velocidade e Eficiência: Sem a necessidade de renderizar componentes visuais, os navegadores headless podem carregar e processar páginas mais rapidamente. Isso os torna ideais para raspar grandes volumes de dados ou executar testes automatizados em escala.
- Prontos para Automação: Navegadores headless são construídos com a automação em mente. Muitos oferecem APIs ou frameworks que permitem aos desenvolvedores simular ações do usuário, como clicar em botões, preencher formulários ou navegar por páginas.
- Escalabilidade: Por serem leves, você pode executar várias instâncias de navegadores headless simultaneamente, tornando-os perfeitos para tarefas que exigem escalabilidade, como raspar milhares de páginas.
Os 10 Melhores Navegadores Headless para Web Scraping
Quando se trata de web scraping, nem todos os navegadores headless são iguais. Aqui estão as principais opções a considerar para coleta de dados eficiente e escalável:
1. Puppeteer
Puppeteer é uma biblioteca JavaScript que fornece uma API de alto nível para controlar o Chrome ou Firefox por meio do Protocolo DevTools ou WebDriver BiDi. É ideal para lidar com sites pesados em JavaScript ou executar tarefas complexas de automação de navegadores.
●Linguagens Suportadas: JavaScript
|
Prós |
Contras |
|
API de alto nível para automação do Chrome |
Limitado a navegadores baseados no Chromium |
|
Suporta interações avançadas, como clicar em botões, tirar screenshots e executar JavaScript |
Requer ambiente Node.js |
|
Comunidade ativa e atualizações regulares |
Sem suporte integrado para múltiplos navegadores |
2. Playwright

Playwright, criado pela Microsoft, é uma alternativa poderosa ao Puppeteer. Ele suporta vários navegadores, incluindo Chromium, Firefox e WebKit, tornando-o uma ferramenta versátil para web scraping.
●Linguagens Suportadas: JavaScript, TypeScript, Python,.NET e Java.
|
Prós |
Contras |
|
Capacidades integradas de interceptação de rede |
Processo de aprendizado mais exigente para iniciantes |
|
Emulação móvel integrada |
Requer mais configuração em comparação com o Puppeteer |
|
Mecanismo de espera automática poderoso |
Menos integrações de terceiros do que o Selenium |
3. Selenium
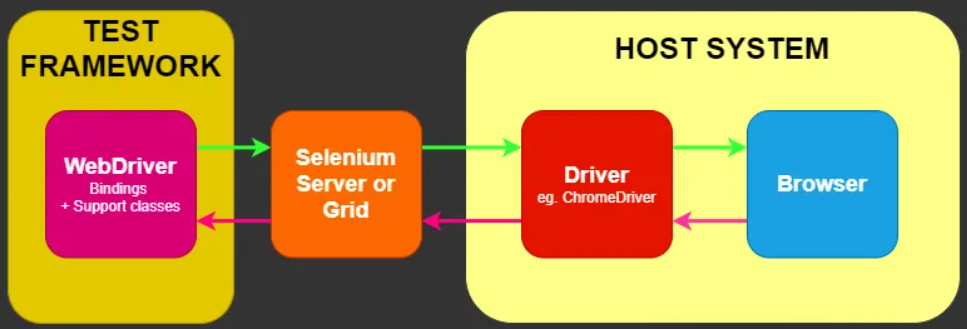
Selenium é um poderoso framework de automação de navegadores que integra várias ferramentas e bibliotecas para automação web. Projetado para cumprir a especificação W3C WebDriver, ele oferece uma API compatível com todos os principais navegadores. Embora seja conhecido principalmente para testes automatizados, seu modo headless o torna uma escolha sólida para web scraping, especialmente para tarefas que envolvem envios de formulários e interações complexas do usuário.
●Linguagens Suportadas: Python, Java, C#, Ruby e JavaScript.
|
Prós |
Contras |
|
Suporta múltiplos navegadores (Chrome, Firefox, Safari, Edge) |
Mais lento que Puppeteer ou Playwright |
|
Grande comunidade e documentação extensa |
Consumo de recursos mais alto |
|
Amplamente reconhecido na indústria |
Requer drivers externos (por exemplo, GeckoDriver, ChromeDriver) |
4. Bright Data Scraping Browser
Bright Data Scraping Browser é um navegador headless poderoso e de nível empresarial, projetado para web scraping em grande escala. Ele oferece gerenciamento integrado de proxies, bypass avançado de detecção de bots e ferramentas de automação para agilizar a coleta de dados. Isso o torna uma excelente escolha para empresas que precisam de soluções de web scraping confiáveis e eficientes.
●Linguagens Suportadas: Python, Node.js (JavaScript), e Java/C#
|
Prós |
Contras |
|
Bypass avançado de detecção de bots |
Serviço pago |
|
Suporte integrado a proxies |
Requer configuração e configuração |
|
Otimizado para scraping em grande escala |
Não é open-source |
5. Headless Chrome
Headless Chrome não é um navegador independente, mas um modo do Google Chrome que funciona sem uma interface gráfica. Como parte do Google Chrome, é uma das ferramentas mais populares para web scraping. É confiável, rápido e fácil de configurar.
●Linguagens Suportadas: JavaScript, Python (via Puppeteer ou Selenium), Java, C#, Ruby, Go e .NET.
|
Prós |
Contras |
|
Rápido e confiável |
Limitado a scraping baseado no Chrome |
|
Suporte direto da Google |
Requer configuração manual para recursos avançados |
|
Suporta várias linguagens por meio de bibliotecas de terceiros |
Pode ser intensivo em recursos para operações em grande escala |
6. Headless Firefox
Headless Firefox é um modo do Mozilla Firefox que opera sem uma interface gráfica, permitindo interações automatizadas com páginas da web por meio de scripts. Assim como o Headless Chrome, é amplamente usado para web scraping, testes automatizados e automação de navegadores. Pode ser controlado por Selenium, SlimmerJS e W3C WebDriver. É uma ferramenta poderosa para desenvolvedores que trabalham em projetos web.
●Linguagens Suportadas: JavaScript, Python (via Selenium).
|
Prós |
Contras |
|
Funciona com o motor Gecko do Firefox |
Mais lento que navegadores headless baseados no Chrome |
|
Suporta execução de JavaScript |
Requer configuração adicional |
|
Funcionalidade semelhante ao Headless Chrome |
Menos popular que outras ferramentas |
7. chromedp
Chromedp é uma maneira mais rápida e simples de controlar navegadores que suportam o Protocolo Chrome DevTools em Go, sem dependências externas. É uma ótima escolha para tarefas leves de scraping e automação. No entanto, a falta de suporte a múltiplos navegadores limita sua flexibilidade para alguns usuários.
●Linguagens Suportadas: Go.
|
Prós |
Contras |
|
Implementação nativa em Go |
Limitado a scraping baseado no Chrome |
|
Leve e eficiente |
Requer conhecimento em desenvolvimento Go |
|
Dependências mínimas |
Falta de suporte a múltiplos navegadores |
8. Cypress
Cypress é principalmente um framework de teste, mas pode ser usado para web scraping em cenários específicos. Ele oferece automação integrada, depuração em tempo real e uma API poderosa para interagir com páginas da web. No entanto, não é otimizado para scraping em grande escala como alguns outros navegadores headless.
●Linguagens Suportadas: JavaScript.
|
Prós |
Contras |
|
Framework de teste fácil de usar |
Não projetado para scraping em grande escala |
|
Mecanismos integrados de espera e repetição |
Suporte limitado a navegadores (baseados no Chrome) |
|
Capacidades robustas de depuração |
Requer GUI para algumas interações |
9. Zombie.js
Zombie.js é um framework leve e compatível com Node.js para testes automatizados de JavaScript no lado do cliente. Ideal para web scraping básico, ele apresenta uma API abrangente com suporte integrado para cookies, abas, autenticação e asserções, garantindo cenários de teste eficientes e robustos.
●Linguagens Suportadas: JavaScript.
|
Prós |
Contras |
|
API totalmente funcional |
Desenvolvimento menos ativo nos últimos anos |
|
Leve e de alta velocidade |
Recursos limitados do navegador |
|
Integração com projetos Node.js |
Não é apropriado para cenários que exigem renderização real do navegador |
10. HtmlUnit
HtmlUnit é um navegador headless baseado em Java que facilita a interação avançada com sites por meio de aplicativos Java. Ele permite tarefas como envio de formulários, navegação por hiperlinks e acesso detalhado ao conteúdo e estrutura da página, permitindo manipulação e análise abrangente de páginas da web.
●Linguagens Suportadas: Java.
|
Prós |
Contras |
|
Leve e rápido |
Suporte limitado a JavaScript |
|
Melhorias contínuas |
Comunidade menos ativa |
|
Suporta bibliotecas AJAX complexas; simula Chrome, Firefox ou Edge com base na configuração |
Pode ter dificuldade em lidar com sites modernos com execução pesada de JavaScript |
Perguntas Frequentes
1. Como Controlar um Navegador Headless para Testes e Web Scraping?
Controlar um navegador headless geralmente envolve o uso de APIs ou frameworks. Por exemplo:
- Puppeteer: Use sua biblioteca Node.js para scriptar interações como navegar por páginas e extrair dados.
- Selenium: Escreva scripts em sua linguagem de programação preferida para automatizar ações do navegador.
- Playwright: Aproveite seu suporte a múltiplos navegadores para lidar com cenários complexos.
2. Qual é o Melhor Navegador Headless Leve?
Se velocidade e eficiência de recursos são suas prioridades, considere usar Headless Chrome ou PhantomJS. Enquanto o Headless Chrome é mantido ativamente e suporta padrões web modernos, o PhantomJS ainda é útil para tarefas básicas.
3. Um Navegador de Impressão Digital (Modo Headless) Pode Ser Usado como um Verdadeiro Navegador Headless?
Um navegador de impressão digital no modo headless oferece funcionalidades semelhantes a um navegador headless tradicional, mas não é exatamente o mesmo. Embora permita a navegação automatizada sem uma interface visível, ele também retém e modifica impressões digitais para reduzir os riscos de detecção. No entanto, alguns recursos avançados de automação disponíveis em navegadores headless tradicionais podem não ser totalmente suportados.
Resumo
Navegadores headless são ferramentas indispensáveis para web scraping, oferecendo velocidade, eficiência e escalabilidade. Se você é um iniciante ou um desenvolvedor experiente, escolher o navegador headless certo pode fazer toda a diferença em seus projetos de scraping. Para web scraping em grande escala, combinar um navegador headless com o AdsPower pode ajudá-lo a evitar detecções ao mascarar impressões digitais, garantindo uma automação mais suave. Experimente o AdsPower gratuitamente hoje e leve sua eficiência de scraping a outro nível!
As pessoas também leem
- Navegadores Antidetecção para Afiliados: Evite Banimentos e Aumente o ROI
- 10 Melhores Navegadores Anônimos para Navegação Privada e Segura na Web
- Top 8 Modelos de Negócios de Afiliados: Como Escolher o Melhor para o Seu Negócio (Guia 2025)
- Para Iniciantes: Como Obter Airdrops de Criptomoedas em 2025
- Guia para Compradores: Proteja as Contas de Facebook Adquiridas
