
How to Scrape Instagram? 3 Ways to Get The Most Out Of Your Scrapping Efforts
With over 1.3 Billion users, Instagram is a goldmine of valuable data for businesses to use for market research, lead generation, and performance monitoring. But scraping Instagram to get this data is the tricky part.
The procedure is not straightforward and has a lot of complexities either due to Instagram policies or technical ambiguities.
This guide answers how to scrape Instagram by introducing three ways involving low and heavy code methods and a no-code method.
Is Instagram Scraping Legal?
The answer to the question “Is Instagram scraping legal?” is yes and no at the same time, as it comes down to the type of data you’re scraping. If you want to scrape Instagram for Publicly available data, the answer is yes.
But if you’re scraping Instagram for private data that requires an Instagram login, then that’s explicitly forbidden and you might face account suspension and in the worst cases, legal action. But even for Public data, you must ensure a legal method of scraping.
To scrape Instagram for legal data you can use the APIs provided by Instagram. These include the Instagram Graph API and Instagram Basic Display API.
The Graph API lets you manage and extract data about business and creator accounts. Whereas the Basic Display API gives you read-only access to basic user information. Both these APIs adhere to Instagram’s policies regarding scraping so scraping Instagram using them is fully legal.
However, if you use non-public APIs or illicit means that access the platform without prior permission and often disguise the scraper to appear as an ordinary user, then that falls under unauthorized scraping and violates Instagram’s Terms of Service.
So before you start scraping Instagram, step back and think to yourself “Does Instagram allow scraping” and make sure you tread carefully while at it.
Which Instagram Data Can You Easily Scrape?
Before showing you how to scrape data from Instagram, let's first discover what data is legally scrapable from the platform. Legal Instagram web scraping can get you access to these three categories of data:
-
Hashtags: You can get the top performing or recent photos and videos that are tagged with a specific hashtag in their caption.
-
Profiles: You can get profile data such as posts, media count, and followers/following count.
-
Posts: You can get metrics such as comment count, likes count, profile ID, publishing date, and URL.
3 Ways to Scrape Instagram
Here are three ways to scrape Instagram. Choose the one that suits your needs and resources:
Scraping Instagram Using Instagram API
Here’s a step-by-step guide about how to scrape Instagram but make sure you fulfill the following requirements first:
-
An Instagram Business/Creator Account
-
A Facebook Page linked to the Instagram Business/Creator Account
-
A Facebook Developer account to use the Instagram Graph API
-
A registered Facebook App setup with minimum settings
Once you are done with these prerequisites, the next stages look like this.
Add Facebook Login Functionality:
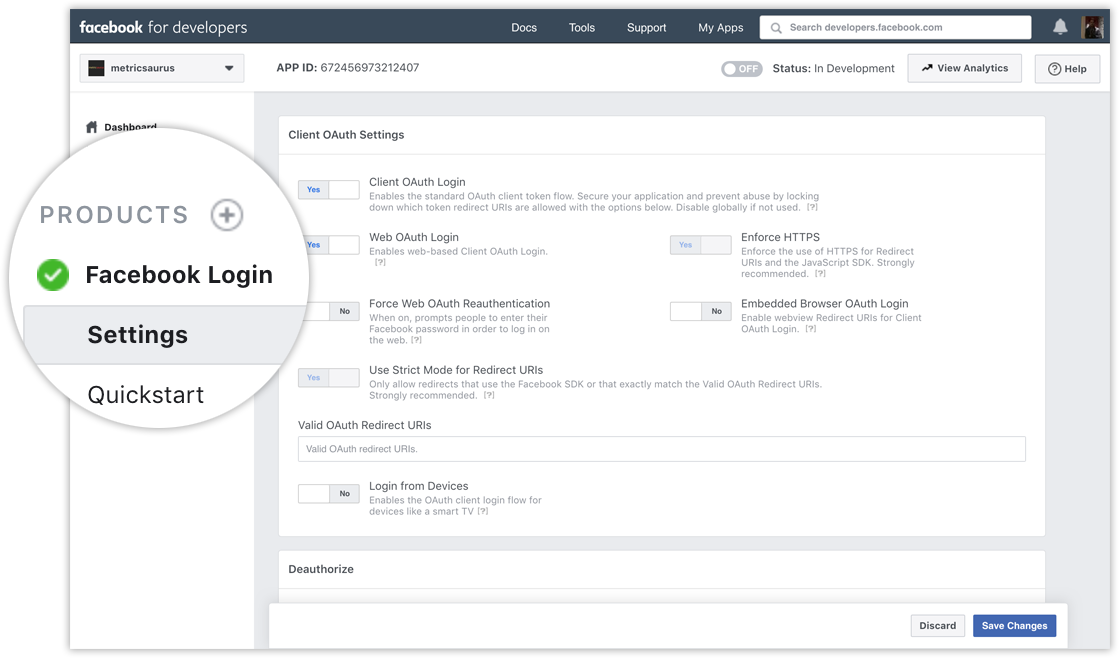
Navigate to your Facebook App’s dashboard and click on the “Product +” button from the panel on the left side of the window. From there add the Facebook Login Product. For now, don’t change the settings for this product and leave them on default.
Next, you’ll have to Implement Facebook Login in your app with the help of Facebook Login Documentation and make sure your login procedure requests these two basic permissions:
Generate Access Token:
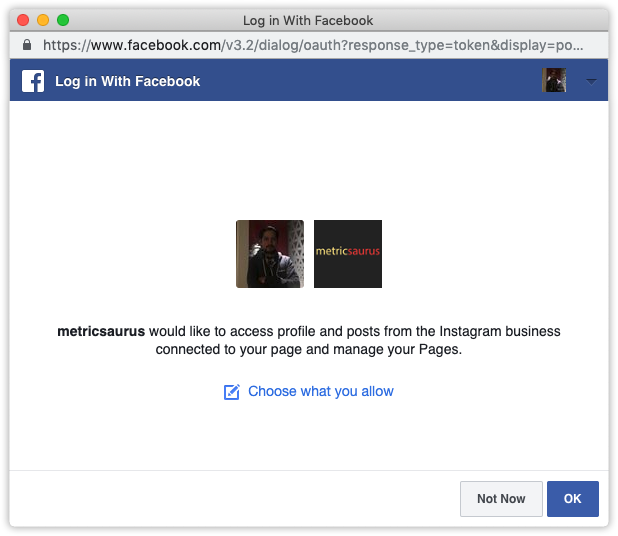
Performing actions from the app dashboard on the Instagram account requires a User Access Token. On the right side of the dashboard page, open the User or Page dropdown and select Get User Access Token.
A popup window will appear informing that an app (in this case your app) is asking for the above-mentioned permissions. Simply press the Continue or OK button and you’ll get the User Access Token in the Access Token field in your dashboard.
Now using the User Access Token we’ll execute a few basic queries on the Instagram Account.
1. Get Facebook Page ID:
First, we need the Facebook Page’s ID that is connected to the Instagram Business account. For this, run the following Get query in the dashboard.
This will return the name and ID of the Facebook Pages belonging to the Facebook user. The output will look like this.
Copy the ID of the page that’s connected to the Instagram Business Account.
2. Get Instagram Business Account ID:
Using the Facebook ID type the following script in the command bar and press submit.
You’ll get the following output.
3. Get Media Objects of the Instagram Account:
Copy the Instagram ID from the output and execute the following script to get the IDs of all stories currently posted on the Instagram Business Account.
The output will contain an ID for each story.
This was just one example. Using Instagram Graph API you can also obtain other information such as an Instagram user’s metadata and perform hashtag research.
Now let’s move to another way of scraping data from Instagram.
Scraping Instagram Using No Code Cloud Scrapper
For those without a coding background, the above method may be difficult to understand, let alone perform. But don’t worry. There are Instagram Scrapers that get the job done without requiring any code.
Here’s how to scrape Instagram using one of those tools called Apify.
Go to the Apify Instagram Scraper page:
Open the Apify Instagram Scraper page and click the Try for Free button.

Sign up on Apify using your email address or Google or Github accounts. This will take you to the Apify Console where the real Instagram scraping occurs.
Gather Target Instagram URLs:
Using the Instagram app or website, collect all the profile URLs of the Instagram accounts you want to scrape. On the Apify console, paste all these URLs in the given input fields one at a time. To enter them all at once you can click the Bulk Edit button.
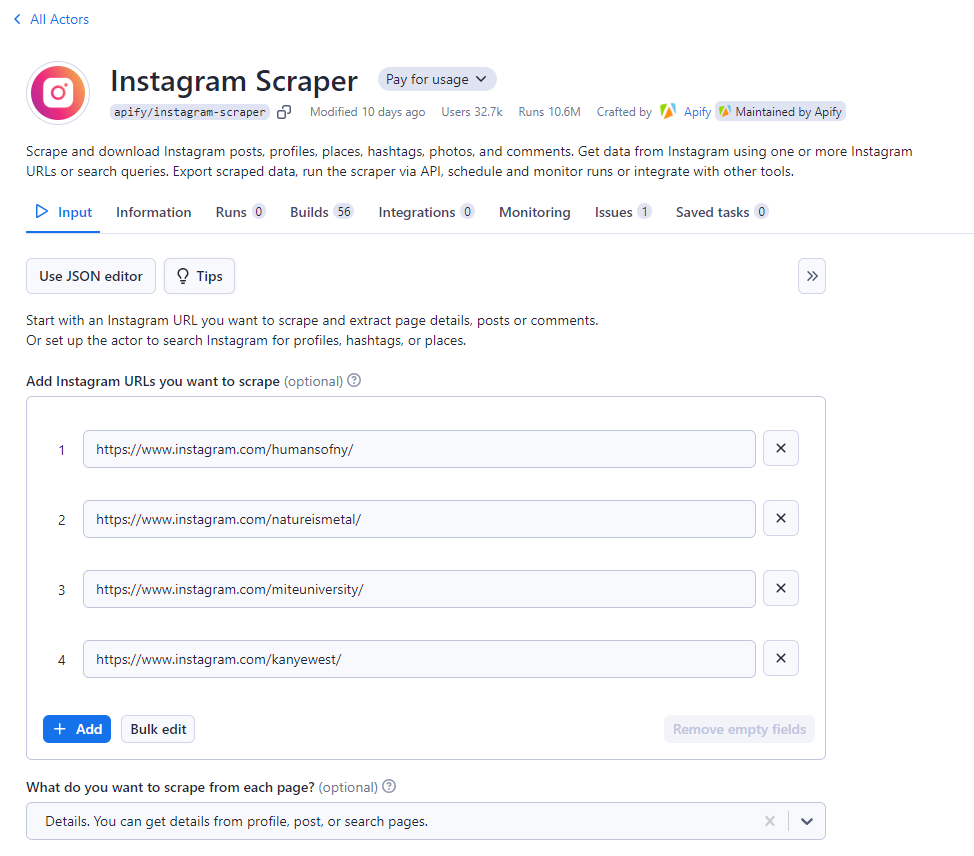
Apify offers three scraping options for the provided URLs, you can scrape posts, and comments or get different details from profiles.
Click Save and Start:
Leave the rest of the settings unchanged and press Save and Start to run the scraper. The result will be in the form of a table containing rows equal to the number of profile URLs you provided with several columns containing profile metadata such as biography, followers count, posts count, reel count, account ID, and verification status to name a few.

Store Results:
Now press the Export Results button and select your desired file format from the pop-up window. You can also clean the data by selecting or omitting fields that you don’t require. After that, you can download the results, view them in a new tab, or share them through a link.

Scraping Instagram Using a Programming Language
Building your own Instagram scraper can be the most efficient solution if your requirements are nontypical and you have sound programming knowledge or have a developer in your team. You can do that using any programming language coupled with a web scraping framework.
This guide demonstrates how to scrape Instagram using Python and Selenium, a browser automation framework.
Import Essential Libraries:
To begin, import basic libraries including Selenium, its webdriver, and Selenium-Stealth to prevent detection.
The pprint library will help us print the output neatly for increased readability.
Collect Instagram Usernames:
Make a list and add the usernames of the Instagram profiles you are targeting.
The output variable is a dictionary that we’ll use to store the results.
Define the main function:
The main function will traverse the usernames list one at a time and call the scrape function on each username.
Define a function to manage browser settings:
This function will adjust the browser setting before each scraping request to add anonymity to evade detection by Instagram. These changes include rotating proxies, configuring Selenium-Stealth settings, and creating an artificial user-agent.
Define a function for Scraping:
The scrape() function called in the main function takes a single Instagram username as an argument and creates a profile endpoint that we’ll use to send a request using the Chrome browser made through the prepare_browser() function.
We’ll also check for the status of the request. If your request was redirected to the login page this means the request failed. Whereas if there was no login string, the request was successful and the result will be parsed as JSON and sent to the parse_data() function along with the username.
Define the parse_data() function:
This function parses the JSON data in the user_data argument to get the desired data field. In this example, we are scraping for the user’s full name, account category, follower count, and post captions.
Write the driver code:
The driver code kicks off the scraping process, extracts the data into the output variable, and calls the pprint() function on it to display it in a pretty way.
Bypass Detection With AdsPower Antidetect Browser
Instagram is strict when it comes to scraping and gives very limited access to public data on its platform. This includes basic level information such as profile ID, followers count, likes, and comment count. Digging deeper than that requires a login which goes against Instagram policies and can lead to account suspension.
This is where AdsPower comes in handy by helping you maintain a low profile when scraping data from Instagram that may have a chance of violating Instagram policies. AdsPower uses antidetect techniques such as IP rotation and rate limiting to evade anti-scraping measures.
So next time you're scraping Instagram using a no-code tool or unofficial Instagram APIs make sure to use AdsPower antidetect browser to bypass detection.
Conclusion
Instagram allows scraping only for the publicly available data on its platform for which it provides two APIs. But these APIs offer a very basic level of scraping without letting you scrape data from Instagram that's actually relevant.
This leaves us with third-party web scrapers or making your own scraper using programming languages. However, scraping Instagram using these unofficial methods has chances of detection so make sure you use AdsPower antidetect browser for added protection.

İnsanlar Ayrıca Okuyun
- Shopify Scraper Guide: Two Ways With and Without Code
- How to Scrape Facebook: 2 Easy Methods for Coders & Non-Coders
- Here’s How to Scrape Reddit in 2 Different Yet Effective Ways
- Pinterest Scraper Simplified: From No-Code to Coding Pinterest Scraping Techniques
- Is It Legal to Scrape Amazon? 6 Crucial Tips & Considerations
