
6 Tips For Seamless Ecommerce Web Scraping
Ecommerce web scraping is a sure-shot tool for businesses to gather necessary insights into the market and improve their performance. However, this tool comes with its own set of challenges. These challenges disrupt the scraping process and create hurdles to gathering data smoothly.
On top of that, some websites have measures in place to prevent their data from being scraped and add another layer of complexity to the task. In today’s data-driven world, understanding how to navigate these obstacles is key to staying competitive and profitable.
This blog post offers five essential tips to ensure seamless ecommerce web scraping. These strategies will help you overcome common scraping challenges and efficiently gather the data you need.
So read further and learn how to do web scraping in ecommerce like a pro. But before jumping to the tips, let’s quickly understand the importance of web scraping for ecommerce.
Ecommerce Has the Highest Share in Web Scraping Industry!
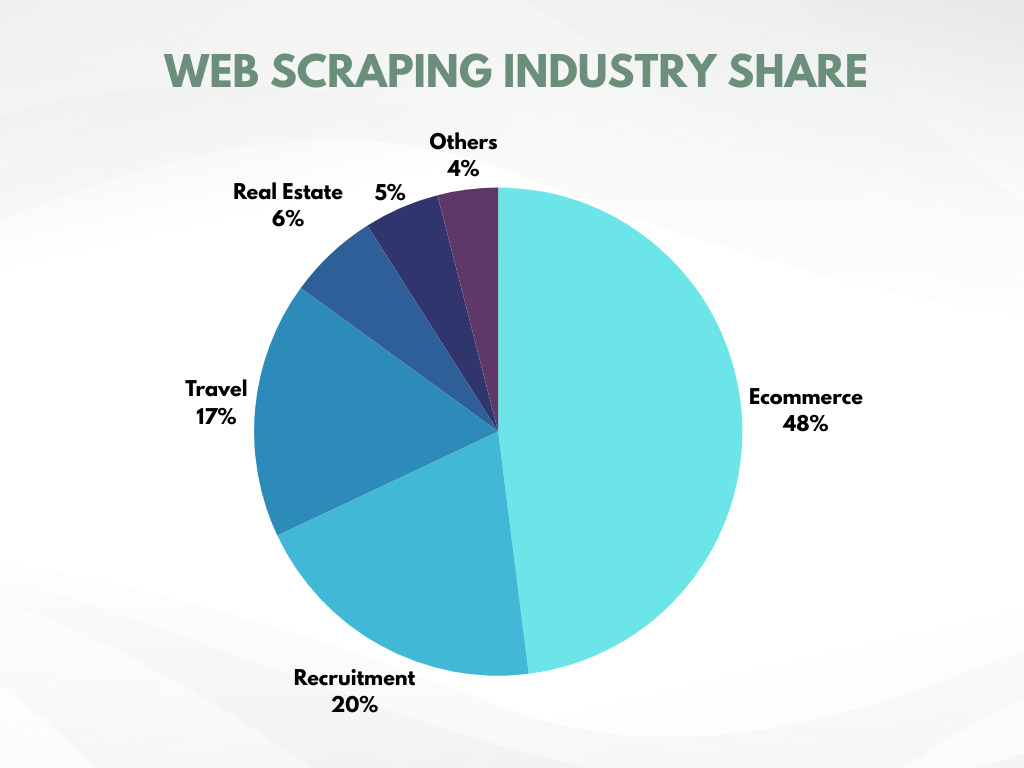
A recent study reveals that the ecommerce industry conducts 48% of all web scraping activities. This figure alone depicts how critical the role of web scraping is in data collection.
Further research indicates that businesses employing data-driven strategies outperform their competition. These businesses heavily rely on web scraping, as it is the only method capable of automatically gathering vast amounts of data from across the internet swiftly and with minimal effort.
5 Tips to Make Ecommerce Web Scraping Seamless + Bonus Tip
Last time, we guided you on how to scrape an ecommerce website. But before you embark on your ecommerce web scraping journey, it's essential to follow certain tips to maximize its effectiveness and yield the best results.
Employ Geo-Targeting
Geo-targeting should be your go-to strategy if you want data insights specific to different regions. Geo-targeting will not only help you develop products according to the problems of region-specific customers, but it will also help you to:
- Identify market opportunities
- Study competition
- Create targeted marketing or pricing strategies
However, you will face challenges when you scrape a high amount of data over and over. This activity can flag the e-commerce web scraper as a bot and might get you blocked. Many websites restrict access to users within their geographic location, and any outside IP addresses are detected and blocked.
The easiest solution to this issue is IP rotation. Web scrapers can mask their IP addresses and appear to access the site from various locations, like real users using proxies. This method also disguises the bot-like behavior of the scraper and prevents it from being blocked.
But if the website you’re dealing with has advanced anti-scraping measures in place, it's necessary to use residential IPs. These are provided by Internet Service Providers in the target region and are less likely to be detected. Free Proxies are not recommended in such cases, as websites often have a list of known free IPs and actively block them.
Slow Down Scraping Speed
Websites often impose limits on the number of requests a user can make within a certain timeframe, which presents a challenge in ecommerce web scraping, where scrapers typically send many loads of requests in a short time period. This rapid request rate is unnatural compared to human browsing speeds and can lead servers to identify the scraper as a bot and ban its IP.
The key to avoiding detection and blocking is to slow down the scraping process. The scraper can mimic human browsing patterns more closely by implementing random breaks between requests or adding wait commands. This approach reduces the risk of triggering the website's anti-bot system and allows for ecommerce scraping without getting blocked.
Dodge CAPTCHAs
Websites generally generate CAPTCHAs in response to what they perceive as suspicious user activity. This halts the ecommerce scraping activities as scrapers generally lack the mechanism to solve CAPTCHAs, and it’s a tough job to automate CAPTCHA solving.
One potential solution is to utilize CAPTCHA-solving services, which employ real people to solve these tests for a fee. However, relying exclusively on these services can become financially burdensome. There are also tools to automate CAPTCHA solving, but these may suffer from reliability issues, particularly as websites continually update their CAPTCHA mechanisms to be more complex.
With such a scenario at hand, the most effective solution is to address the root cause that triggers the generation of CAPTCHAs. The key is to configure your web scraper in such a way that it mimics the behavior of a genuine user. This includes strategies to avoid hidden traps, using proxies and rotating IP addresses and headers, and erasing automation clues, to name a few.
Avoid Anti-Bot Systems
Websites use HTTP header information to create a user fingerprint, which helps identify and monitor users and distinguishes bots from human users.
This header contains a User-Agent string that websites collect when you join their server. This string typically includes details about the browser and device in use. This is not an issue for a regular user since they use common browsers, devices, and operating systems. But since scrapers don’t usually scrape through a standard browser, their UA string gives away their bot identity.
One workaround for this issue is manually editing the User-Agent string through scripting by including common elements in place of the browser name, version, and operating system.
Here’s how to do it;
But repeated requests from the same UA string can still get you caught. So, for additional safety, you can use a list of different user agent strings in your script and randomly rotate through them to avoid alarming the anti-bot system.
For a more foolproof solution, you can use browser automation tools like Selenium or Puppeteer to scrape using an anti-detect browser like AdsPower. These browsers have built-in measures to protect against fingerprinting using a number of techniques that include masking, modifying, and rotating the user's fingerprint.
Be Mindful of Dynamic Websites
Dynamic websites change their webpage content and layout based on the visitors. Even for the same visitor, dynamic websites show different web pages on separate visits based on factors such as their:
- Location
- Settings
- Time zones
- Or user actions such as shopping habits
In contrast, static websites display the same content to all users. This poses a challenge in ecommerce web scraping as the webpages of the dynamic websites to be scraped don’t exist until loaded on a browser.
You can overcome this challenge by automating Selenium to load the dynamic webpages on a headful browser and then scrape their content. But waiting for all the webpages to load fully on a real browser is going to take forever since Selenium doesn’t support asynchronous clients.
Alternatively, you can use Puppeteer or Playwright, which allow for asynchronous web scraping where the scraper can request other web pages while the requested web pages load. This way, the scraper doesn’t have to wait for the response of a webpage, and the process becomes much faster.
Bonus Tip ⇒ Use AdsPower for Risk-Free Ecommerce Web Scraping
While these tips can help to some extent with the challenges of scraping ecommerce websites, they are not completely foolproof. For instance, even scraping at slower speeds or during off-peak hours may not evade detection by websites with advanced anti-scraping mechanisms.
Similarly, IP rotation and proxies can still leave scrapers vulnerable to detection.
All these limitations highlight the need for a foolproof solution to ensure a seamless ecommerce web scraping experience. This is exactly what AdsPower is built for. AdsPower has all the techniques to disguise your scraper as a real user to maintain its cover and avoid detection.
It achieves this by masking your scraper's digital fingerprints, which prevents websites from flagging the scraper and generating CAPTCHAs as obstacles. Moreover, AdsPower combines the advantages of both headful and headless browsers to tackle the challenges posed by dynamic websites.
Beyond these features, AdsPower also allows the creation of multiple profiles in parallel to scale up the data extraction process. It also helps automate ecommerce web scraping to save time and resources.
Harness the Power of Data!
While ecommerce web scraping comes with its fair share of challenges, from advanced anti-bot systems to the complexities of dynamic websites, these hurdles can be overcome.
You can enhance your ecommerce web scraping by using effective tips like geo-targeting, slowing down your scraping speed, learning how to bypass anti-bot systems, adapting to dynamic websites, and preventing websites from generating CAPTCHAs. And to make things more robust, there’s no better platform than AdsPower’s anti-detect browser to keep your scraper off the sight of websites.
So, let's put these tips into practice and harness the power of data.

他にも読む記事
- Shopify Scraper Guide: Two Ways With and Without Code
- How to Scrape Facebook: 2 Easy Methods for Coders & Non-Coders
- Here’s How to Scrape Reddit in 2 Different Yet Effective Ways
- Pinterest Scraper Simplified: From No-Code to Coding Pinterest Scraping Techniques
- Is It Legal to Scrape Amazon? 6 Crucial Tips & Considerations
