
5 Effective Ways to Do Web Scraping Without Getting Blocked

Did you know that about 47% of all internet traffic is generated by bots, including web scrapers? In a digital world where data is everything, scraping the web for information has become a necessity for many businesses.
However, as essential as this process is, it comes with its challenges, from CAPTCHAs that block automated access to honeypot traps that lure and expose bots.
But our main focus isn't on these obstacles. We're here to explore effective solutions to bypass them to enable seamless web scraping without getting blocked.
This article outlines five ways for successful web scraping without getting blocked. From using a sophisticated anti detect browser to scheduling your scraping tasks during less busy hours, we cover a range of techniques.
By deploying these methods, not only will you reduce the chances of getting blocked, but you will also improve the efficiency and scale of your web scraping activities.
Let’s dive in and help you collect important data without any hindrances.
Challenges in Web Scraping
The risks and challenges to data scraping range from technical barriers to deliberately set traps by websites. Understanding these challenges is a key step in devising a robust web scraping strategy.
Below, we highlight a few of the most common challenges faced by web scrapers.
5 Ways to Do Web Scraping Without Getting Blocked

While challenges to web scraping are many. Each one of them has solutions to bypass them. Let's explore these techniques and understand how they can facilitate web scraping without getting blocked.
Headless Browser
One way to go about web scraping without getting blocked is the technique called headless web scraping. This approach involves using a headless browser - a type of browser without a Graphical User Interface (GUI). A headless browser can simulate a typical user’s browsing activity, helping you remain undetected by sites that use Javascript to track and block web scrapers.
These browsers are particularly helpful when the target website is loaded with Javascript elements since traditional HTML scrapers lack the ability to render such websites like a real user.
Mainstream browsers like Chrome and Firefox have headless modes, but you’ll still need to tweak their behavior to appear authentic. Furthermore, you can add another layer of protection by combining headless browsers with proxies to conceal your IP and prevent bans.
You can programmatically control headless Chrome through Puppeteer, which provides a high-level API to browse websites and do almost anything on them.
For example, here’s a simple Puppeteer script to create a browser instance, take a screenshot of a webpage, and then close the instance.
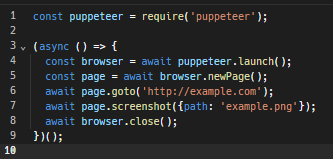
Here’s a detailed tutorial on how to perform headless browsing using Puppeteer.
Scrape During Off-Peak Hours
Scraping involves browsing websites at a very fast pace, a behavior uncommon among regular users. This can lead to high server loads and service slowdowns for others. As a result, website administrators might notice the scraper and kick it out of the server.
So, a smart move for web scraping without getting blocked is to do it during the website’s off-peak hours. This is when sites are usually less on guard. And even if your crawler activities consume a lot of server resources, it might not be enough to exhaust the server and catch admins’ attention.
However, there’s still a chance of getting caught. Some websites may have sophisticated measures in place to monitor user activity even during quieter times. In addition, determining the off-peak hours of a website can be tricky if the information available isn’t up-to-date.
Use Anti Detect Browser
An anti detect browser is a comprehensive tool designed to keep users anonymous and hide their online activities from the websites they visit. It works by masking or altering the user's browser's digital fingerprint, which is typically made up of details like browser type, plugins, screen resolution, and timezone, all used by websites to track user activities.
This makes anti detect browsers ideal for web scraping without getting blocked. However, it's important to note that these browsers only reduce detection risks; they aren't completely infallible against all websites. Therefore, choosing the best anti detect browser for web scraping is key to minimizing the chances of being detected.
A good anti detect browser for web scraping is AdsPower. It uses specific techniques to evade anti-scraping measures, such as:
Besides these features, AdsPower also offers additional benefits like scraping automation and multiple browser profiles to speed up the scraping process.
Automate CAPTCHA Solving or Use Paid Services
To bypass CAPTCHAs while web scraping without getting blocked, you have several options. First, consider whether you can obtain the needed information without accessing CAPTCHA-protected sections, as coding a direct solution is challenging.
However, if accessing these sections is crucial, you can use CAPTCHA-solving services. These services, such as 2Captcha and Anti Captcha, employ real humans to solve CAPTCHAs for a fee-per-solved test. But remember that solely depending on these services can put a dent in your wallet.
Alternatively, dedicated web scraping tools like ZenRows' D and Oxylabs’ data crawling tool can automatically bypass CAPTCHAs. These tools use advanced machine learning algorithms to solve CAPTCHAs to ensure that your scraping activities continue smoothly.
Honeypot Traps
To effectively deal with honeypot traps while web scraping without getting blocked, it's key to recognize and avoid them. Honeypot traps are mechanisms designed to lure and identify bots, often presenting as invisible links in a website's HTML code that are hidden from people but detectable by web scrapers.
One strategy is to program your crawler or scraper to identify links that are made invisible to human users through CSS properties. For example, avoid following text links that blend into the background color, as this is a tactic to deliberately hide links from human eyes.
Here’s a basic JavaScript function to spot such invisible links.
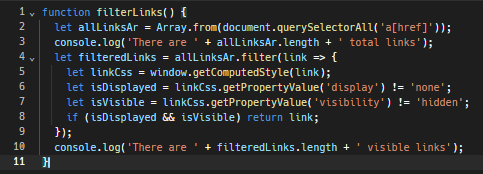
Additionally, respecting the website's robots.txt file is crucial. This file is intended for bots and lays out the do’s and don’ts of scraping. It offers information about the areas of the site that are off-limits and the parts where scraping is allowed. Following these rules is a good practice and can help you steer clear of honeypot traps.
Wrapping Up!
Sure, there are anti-scraping measures that keep us from accessing valuable data on target websites and sometimes get us permanently banned, too. But none of these challenges are impossible to overcome.
You can use tools like headless browsers to mimic real browsing, scrape during less busy hours to avoid detection, and use anti detect browsers like AdsPower to hide your fingerprints. Moreover, there are also ways to bypass CAPTCHAs and dodge honeypot traps.
With these tactics, successful web scraping without getting blocked is easily achievable. So, let's move beyond the hit-or-miss approach and start scraping the smart way.

La gente también leyó
- Shopify Scraper Guide: Two Ways With and Without Code
- How to Scrape Facebook: 2 Easy Methods for Coders & Non-Coders
- Here’s How to Scrape Reddit in 2 Different Yet Effective Ways
- Pinterest Scraper Simplified: From No-Code to Coding Pinterest Scraping Techniques
- Is It Legal to Scrape Amazon? 6 Crucial Tips & Considerations
