
10 trình duyệt không đầu tốt nhất để thu thập dữ liệu web: Ưu và nhược điểm
Xem nhanh
Bạn muốn tăng tốc quá trình thu thập dữ liệu web của mình? Trình duyệt không đầu là vũ khí bí mật của bạn. Khám phá cách chúng hoạt động, lý do tại sao chúng tuyệt vời và trình duyệt nào sẽ đưa trò chơi thu thập dữ liệu của bạn lên một tầm cao mới.
Bạn đã bao giờ cần trích xuất hiệu quả một lượng lớn dữ liệu trực tuyến, chỉ để thấy rằng các trình duyệt truyền thống làm bạn chậm lại chưa? Từ theo dõi giá đến phân tích cạnh tranh, thu thập dữ liệu web rất quan trọng trong việc tự động hóa việc thu thập dữ liệu. Tuy nhiên, sử dụng trình duyệt thông thường để thu thập dữ liệu có thể chậm và không hiệu quả. Khi tốc độ và tự động hóa là vấn đề quan trọng, giải pháp tốt nhất là gì?
Trong hướng dẫn này, chúng ta sẽ khám phá 10 trình duyệt không đầu tốt nhất để thu thập dữ liệu web, phân tích điểm mạnh và điểm yếu của chúng để giúp bạn chọn đúng công cụ cho nhu cầu của mình.
Trình duyệt không đầu là gì?

Nói một cách đơn giản, trình duyệt không đầu là trình duyệt web không có giao diện người dùng đồ họa (GUI). Nó hoạt động ở chế độ nền, lấy và hiển thị các trang web giống như trình duyệt thông thường nhưng không hiển thị chúng trên màn hình của bạn. Điều này làm cho trình duyệt không đầu hoàn hảo cho các tác vụ như thu thập dữ liệu web, thử nghiệm tự động và giám sát hiệu suất.
Nhân tiện, chế độ không đầu của trình duyệt chống phát hiện, như AdsPower, cung cấp các khả năng tương tự như trình duyệt không đầu truyền thống nhưng có khả năng ẩn danh được cải tiến. Trong khi các trình duyệt không đầu truyền thống thường bị gắn cờ do thiếu dấu vân tay, chế độ không đầu của AdsPower giúp bỏ qua phát hiện bằng cách che giấu và sửa đổi dấu vân tay kỹ thuật số, khiến các yêu cầu của bạn xuất hiện như thể chúng đến từ những người dùng hợp pháp, duy nhất.
|
Use Case |
AdsPower Headless Mode |
Traditional headless browsers |
|
Multi-account management |
✅ Yes |
❌ No |
|
Bypassing bot detection |
✅ Yes |
❌ No |
How to Start AdsPower in Headless Mode?
1. Go to API Settings in AdsPower and click Generate or Reset to obtain your API key.

2. Khởi động AdsPower ở chế độ Headless (Mở CMD hoặc Terminal trong thư mục gốc AdsPower)
- Windows: "AdsPower Global.exe" --headless=true --api-key=XXXX --api-port=50325
- macOS: "/Applications/AdsPower Global.app/Contents/MacOS/AdsPower Global" --args --headless=true --api-key=XXXX --api-port=50325
- Linux: adspower_global --headless=true --api-key=XXX --api-port=50325
3. Kiểm tra địa chỉ trả về trong dòng lệnh để xác nhận khởi động thành công.

Hướng dẫn đầy đủ: AdsPower API Docs – Headless Mode
Trình duyệt không đầu khác với trình duyệt thông thường như thế nào?
Hãy nghĩ theo cách này: Trong khi trình duyệt thông thường được thiết kế để tương tác với con người—với các nút để nhấp, các trang để cuộn và hình ảnh để chiêm ngưỡng—trình duyệt không đầu loại bỏ các yếu tố trực quan. Chúng chỉ tập trung vào chức năng, cho phép bạn tương tác theo chương trình với các trang web. Có những khác biệt chính khiến trình duyệt không đầu đặc biệt phù hợp với các tác vụ tự động hóa:
- Không có GUI: Trình duyệt không có giao diện người dùng hoạt động mà không hiển thị trang web trực quan, điều này có lợi cho môi trường máy chủ vì nó làm giảm chi phí tính toán và mức tiêu thụ tài nguyên. Tuy nhiên, việc thiếu phản hồi trực quan thực sự có thể khiến việc khắc phục sự cố trở nên khó khăn hơn vì không có tín hiệu trực quan nào giúp chẩn đoán sự cố.
- Tốc độ và hiệu quả: Không cần phải hiển thị các thành phần trực quan, trình duyệt không đầu có thể tải và xử lý các trang nhanh hơn. Điều này làm cho chúng trở nên lý tưởng để thu thập khối lượng dữ liệu lớn hoặc chạy các thử nghiệm tự động ở quy mô lớn.
- Sẵn sàng tự động hóa: Trình duyệt không đầu được xây dựng với mục đích tự động hóa. Nhiều trình duyệt cung cấp API hoặc khung cho phép các nhà phát triển mô phỏng các hành động của người dùng như nhấp vào nút, điền vào biểu mẫu hoặc điều hướng qua các trang.
- Khả năng mở rộng: Vì chúng nhẹ nên bạn có thể chạy nhiều phiên bản trình duyệt không đầu cùng lúc, khiến chúng trở nên hoàn hảo cho các tác vụ đòi hỏi khả năng mở rộng, chẳng hạn như thu thập hàng nghìn trang.
10 trình duyệt không đầu tốt nhất để thu thập dữ liệu web
Khi nói đến việc thu thập dữ liệu web, không phải tất cả các trình duyệt không đầu đều được tạo ra như nhau. Sau đây là các tùy chọn hàng đầu cần cân nhắc để thu thập dữ liệu hiệu quả và có thể mở rộng:
1. Puppeteer
Puppeteer là một thư viện JavaScript cung cấp API cấp cao để kiểm soát Chrome hoặc Firefox qua DevTools Protocol hoặc WebDriver BiDi. Nó lý tưởng để xử lý các trang web nặng về JavaScript hoặc thực hiện các tác vụ tự động hóa trình duyệt phức tạp.
- Supported Languages: JavaScript
|
Ưu điểm |
Nhược điểm |
|
API cấp cao cho tự động hóa Chrome |
Chỉ giới hạn ở trình duyệt dựa trên Chromium |
|
Hỗ trợ các tương tác nâng cao, chẳng hạn như nhấp vào nút, chụp ảnh màn hình và thực thi JavaScript. |
Yêu cầu môi trường Node.js |
|
Cộng đồng năng động và cập nhật thường xuyên |
Không có hỗ trợ đa trình duyệt tích hợp |
2. Playwright

Playwright, do Microsoft tạo ra, là một giải pháp thay thế mạnh mẽ cho Puppeteer. Nó hỗ trợ nhiều trình duyệt, bao gồm Chromium, Firefox và WebKit, khiến nó trở thành một công cụ đa năng để thu thập dữ liệu web.
- Ngôn ngữ được hỗ trợ: JavaScript, TypeScript, Python,.NET, Java.
|
Ưu điểm |
Nhược điểm |
|
Khả năng chặn mạng tích hợp |
Quá trình học đòi hỏi nhiều hơn đối với người mới |
|
Mô phỏng di động tích hợp |
Yêu cầu thiết lập nhiều hơn so với Puppeteer |
|
Cơ chế tự động chờ mạnh mẽ |
v |
3. Selenium
Selenium là một khuôn khổ tự động hóa trình duyệt mạnh mẽ tích hợp nhiều công cụ và thư viện khác nhau để tự động hóa web. Được thiết kế để tuân thủ thông số kỹ thuật W3C WebDriver, nó cung cấp API đa ngôn ngữ tương thích với tất cả các trình duyệt web chính. Mặc dù chủ yếu được biết đến với mục đích thử nghiệm tự động, chế độ không có giao diện người dùng của nó khiến nó trở thành lựa chọn mạnh mẽ để thu thập dữ liệu web, đặc biệt là đối với các tác vụ liên quan đến việc gửi biểu mẫu và tương tác phức tạp của người dùng.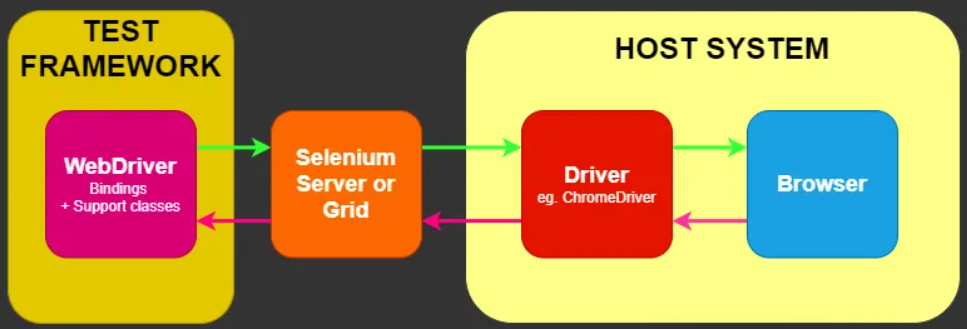
- Ngôn ngữ được hỗ trợ: Python, Java, C#, Ruby, JavaScript.
|
Ưu điểm |
Nhược điểm |
|
Hỗ trợ nhiều trình duyệt (Chrome, Firefox, Safari, Edge) |
Chậm hơn Puppeteer hoặc Playwright |
|
Cộng đồng lớn và tài liệu phong phú |
Tiêu thụ tài nguyên cao hơn |
|
Được công nhận rộng rãi trong ngành |
Yêu cầu trình điều khiển bên ngoài (ví dụ: GeckoDriver, ChromeDriver) |
4. Bright Data Scraping Browser
Bright Data Scraping Browser là trình duyệt không đầu mạnh mẽ, cấp doanh nghiệp được thiết kế để thu thập dữ liệu web quy mô lớn. Nó cung cấp quản lý proxy tích hợp, bỏ qua phát hiện bot tiên tiến và các công cụ tự động hóa để hợp lý hóa việc thu thập dữ liệu. Điều này làm cho nó trở thành lựa chọn tuyệt vời cho các doanh nghiệp cần các giải pháp thu thập dữ liệu web đáng tin cậy và hiệu quả.
- Ngôn ngữ được hỗ trợ: Python, Node.js (JavaScript), and Java/C#
|
Ưu điểm |
Nhược điểm |
|
Advanced anti-bot bypassing |
Paid service |
|
Integrated proxy support |
Requires setup and configuration |
|
Optimized for large-scale scraping |
Not open-source |
5. Headless Chrome
Headless Chrome không phải là trình duyệt độc lập mà là chế độ của Google Chrome chạy mà không cần giao diện đồ họa. Là một phần của Google Chrome, đây là một trong những công cụ phổ biến nhất để thu thập dữ liệu web. Nó đáng tin cậy, nhanh chóng và dễ thiết lập.
- Ngôn ngữ được hỗ trợ: JavaScript, Python (via Puppeteer or Selenium), Java, C#, Ruby, Go, and .NET.
|
Ưu điểm |
Nhược điểm |
|
Nhanh chóng và đáng tin cậy |
Giới hạn trong việc thu thập dữ liệu dựa trên Chrome |
|
Hỗ trợ trực tiếp từ Google |
Yêu cầu cấu hình thủ công cho các tính năng nâng cao |
|
Hỗ trợ nhiều ngôn ngữ thông qua các thư viện của bên thứ ba |
Có thể tốn nhiều tài nguyên cho các hoạt động quy mô lớn |
6. Headless Firefox
Headless Firefox là chế độ của Mozilla Firefox hoạt động mà không cần giao diện người dùng đồ họa, cho phép tương tác tự động với các trang web thông qua các tập lệnh. Giống như Headless Chrome, nó được sử dụng rộng rãi để thu thập dữ liệu web, thử nghiệm tự động và tự động hóa trình duyệt. Nó có thể được điều khiển bởi Selenium, SlimmerJS và W3C WebDriver. Đây là một công cụ mạnh mẽ dành cho các nhà phát triển làm việc trên các dự án web.
- Ngôn ngữ được hỗ trợ: JavaScript, Python (via Selenium).
|
Ưu điểm |
Nhược điểm |
|
Hoạt động với công cụ Gecko của Firefox |
Chậm hơn trình duyệt không đầu dựa trên Chrome |
|
Hỗ trợ thực thi JavaScript |
Yêu cầu thiết lập bổ sung |
|
Chức năng tương tự như Headless Chrome |
Ít phổ biến hơn các công cụ khác |
7. chromedp
Chromed là một cách nhanh hơn, đơn giản hơn để điều khiển các trình duyệt hỗ trợ Chrome DevTools Protocol trong Go mà không cần phụ thuộc bên ngoài. Đây là lựa chọn tuyệt vời cho các tác vụ tự động hóa và thu thập dữ liệu nhẹ. Tuy nhiên, việc thiếu hỗ trợ nhiều trình duyệt hạn chế tính linh hoạt của nó đối với một số người dùng.
- Ngôn ngữ được hỗ trợ: Go.
|
Ưu điểm |
Nhược điểm |
|
Triển khai Go gốc |
Giới hạn trong việc thu thập dữ liệu dựa trên Chrome |
|
Nhẹ và hiệu quả |
Yêu cầu kiến thức phát triển Go |
|
Tối thiểu phụ thuộc |
Thiếu hỗ trợ đa trình duyệt |
8. Cypress
Cypress chủ yếu là một khuôn khổ thử nghiệm nhưng có thể được sử dụng để thu thập dữ liệu web trong các tình huống cụ thể. Nó cung cấp tính năng tự động hóa tích hợp, gỡ lỗi thời gian thực và API mạnh mẽ để tương tác với các trang web. Tuy nhiên, nó không được tối ưu hóa để thu thập dữ liệu quy mô lớn như một số trình duyệt không có giao diện người dùng khác.
- Ngôn ngữ được hỗ trợ: JavaScript.
|
Ưu điểm |
Nhược điểm |
|
Khung thử nghiệm dễ sử dụng |
Không được thiết kế để thu thập dữ liệu quy mô lớn |
|
Cơ chế chờ và thử lại tích hợp |
Hỗ trợ trình duyệt hạn chế (dựa trên Chrome) |
|
Khả năng gỡ lỗi mạnh mẽ |
Yêu cầu GUI cho một số tương tác |
9. Zombie.js
Zombie.js là một khuôn khổ nhẹ, tương thích với Node.js để kiểm tra JavaScript tự động phía máy khách. Lý tưởng cho việc thu thập dữ liệu web cơ bản, nó có API toàn diện với hỗ trợ tích hợp cho cookie, tab, xác thực và xác nhận, đảm bảo các tình huống kiểm tra hiệu quả và mạnh mẽ.
- Ngôn ngữ được hỗ trợ: JavaScript.
|
Ưu điểm |
Nhược điểm |
|
Một API đầy đủ tính năng |
Phát triển lỗi thời và ít hoạt động hơn trong những năm gần đây |
|
Nhẹ và tốc độ cao |
Các tính năng trình duyệt hạn chế |
|
Tích hợp với các dự án Node.js |
Không phù hợp với các tình huống yêu cầu kết xuất trình duyệt thực sự |
10. HtmlUnit
HtmlUnit là trình duyệt không đầu dựa trên Java giúp tương tác nâng cao với các trang web thông qua các ứng dụng Java. Nó cho phép các tác vụ như gửi biểu mẫu, điều hướng siêu liên kết và truy cập chi tiết vào nội dung và cấu trúc trang web, cho phép thao tác và phân tích toàn diện các trang web.
- Ngôn ngữ được hỗ trợ: Java.
|
Ưu điểm |
Nhược điểm |
|
Nhẹ và nhanh |
Hỗ trợ JavaScript hạn chế |
|
Liên tục cải tiến |
Cộng đồng ít hoạt động |
|
Hỗ trợ các thư viện AJAX phức tạp; mô phỏng Chrome, Firefox hoặc Edge dựa trên cấu hình |
Có thể gặp khó khăn khi xử lý các trang web hiện đại có thực thi JavaScript nặng |
FAQ
1. Cách kiểm soát trình duyệt không đầu để kiểm tra và thu thập dữ liệu web?
Kiểm soát trình duyệt không đầu thường liên quan đến việc sử dụng API hoặc khung. Ví dụ:
- Puppeteer: Sử dụng thư viện Node.js của nó để tạo kịch bản cho các tương tác như điều hướng trang và trích xuất dữ liệu.
- Selenium: Viết các kịch bản bằng ngôn ngữ lập trình ưa thích của bạn để tự động hóa các hành động của trình duyệt.
- Playwright: Tận dụng lợi thế của hỗ trợ nhiều trình duyệt để xử lý các tình huống phức tạp.
2. Trình duyệt Headless nhẹ nhất là gì??
Nếu tốc độ và hiệu quả tài nguyên là ưu tiên của bạn, hãy cân nhắc sử dụng Headless Chrome hoặc PhantomJS. Trong khi Headless Chrome được bảo trì tích cực và hỗ trợ các tiêu chuẩn web hiện đại, PhantomJS vẫn hữu ích cho các tác vụ cơ bản.
3. Trình duyệt vân tay (Chế độ không đầu) có thể được sử dụng như một trình duyệt không đầu thực sự không??
Trình duyệt vân tay ở chế độ không đầu cung cấp các chức năng tương tự như trình duyệt không đầu truyền thống nhưng không hoàn toàn giống nhau. Mặc dù cho phép duyệt tự động mà không cần giao diện người dùng có thể nhìn thấy, nhưng nó cũng giữ lại và sửa đổi dấu vân tay để giảm rủi ro phát hiện. Tuy nhiên, một số tính năng tự động hóa nâng cao có sẵn trong trình duyệt không đầu truyền thống có thể không được hỗ trợ đầy đủ.
Tóm lại
Trình duyệt không đầu là công cụ không thể thiếu để thu thập dữ liệu web, cung cấp tốc độ, hiệu quả và khả năng mở rộng. Cho dù bạn là người mới bắt đầu hay nhà phát triển dày dạn kinh nghiệm, việc chọn đúng trình duyệt không đầu có thể tạo ra sự khác biệt lớn trong các dự án thu thập dữ liệu của bạn. Đối với việc thu thập dữ liệu web quy mô lớn, việc ghép nối trình duyệt không đầu với AdsPower có thể giúp bạn tránh bị phát hiện bằng cách che dấu vân tay kỹ thuật số, đảm bảo tự động hóa mượt mà hơn. Hãy dùng thử AdsPower miễn phí ngay hôm nay và đưa hiệu quả thu thập dữ liệu của bạn lên một tầm cao mới!

Mọi người cũng đọc
- 8 mô hình kinh doanh affiliate hàng đầu: Cách chọn mô hình tốt nhất cho doanh nghiệp của bạn (Hướng
- Trình duyệt Antidetect dành cho các nhà tiếp thị liên kết: Tránh lệnh cấm và tăng ROI
- Trình duyệt Antidetect dành cho các nhà tiếp thị liên kết: Tránh lệnh cấm và tăng ROI
- Tối ưu hóa công cụ tìm kiếm: Bí quyết đưa trang Web lên top
- Facebook ra mắt tính năng mới cho phép kiếm tiền từ Stories
