
How to Do Web Scraping Using Javascript: A Comprehensive Guide
Want to learn how to do web scraping using Javascript but have no idea where to begin? Don't worry.
In this blog, we'll provide you with all the necessary information you need to start Javascript scraping. Plus, we'll walk you through a step-by-step process of scraping a website using JavaScript with Puppeteer.
Let's get started.
What is Javascript Scraping?
In today's digital age, JavaScript for web scraping has become an essential skill not only for developers and data enthusiasts. But also for marketers to learn.
At its core, JavaScript scraping is the process of using JavaScript-based libraries or tools to extract valuable data from websites. While you can use other programming languages like Python to scrape a website, Javascript scraping is particularly useful for gathering information from websites that are heavy on JavaScript to display content.
When you scrape a website using JavaScript, you're essentially writing code to automate the process of collecting data from a web browser. It's a powerful method for data extraction, allowing for the collection of vast amounts of information in a relatively short amount of time.
Whether you're looking to analyze market trends, gather competitive intelligence, or collect data to generate leads for your business, data scraping using JavaScript can be an invaluable tool. This method leverages the capabilities of JavaScript, a language deeply embedded in web development, to navigate, select, and extract data from various web pages.
Now, that we understand what Javascript web scraping is, let’s find out what are the ways you can use Javascript to scrape a site.
3 Common Ways to Scrape a Website Using Javascript
There are multiple ways you can use Javascript to scrape a website. But which one should you use? Well, the answer to that depends on your scraping requirements. In this section, we'll explain three common ways people use to scrape a website using Javascript.
Cheerio for Simple Static Websites
Have you seen HTML websites whose content quickly loads in the initial request? Well, that's because they do not contain heavy content like videos or complex animations. While dealing with such static websites, using Cheerio is an ideal choice.
By fetching the raw HTML of the page through an HTTP client, Cheerio allows you to traverse and manipulate the DOM easily.
It's lightweight and fast, primarily because it doesn't need to load the entire browser environment. As we mentioned, this method is perfect for simple, static websites where the data is readily available in the HTML code.
Puppeteer for Scraping Dynamic Content
If you're dealing with a more complex website, one that contains dynamic content like videos and images, or JavaScript-heavy sites where content is dynamically loaded, Puppeteer, a Node library, is the best choice.
Puppeteer uses a headless browser, a web browser without a graphical user interface(GUI), to interact with web pages. This means it can emulate user actions like clicking buttons or scrolling, essential for accessing content that appears as a result of these interactions.
Puppeteer is powerful for scraping modern web applications that rely on AJAX and require a full browser environment to execute JavaScript code and render content.
Scrape a Website Using jQuery
Sometimes, you might not need to scrape large amounts of data. You may need to extract quick information once like scraping certain email addresses. In such cases, jQuery can be a handy tool. Although it's a client-side script running in the browser, you can use jQuery to select and extract data from web pages easily.
This method is particularly useful for ad-hoc scraping tasks. It’s as simple as opening your console, writing a few lines of jQuery code, and extracting the needed information. However, this approach is not suitable for large-scale or automated scraping tasks.
Each of these methods has its own set of advantages and is suitable for different scraping needs. Whether it's a one-off data extraction or a complex scraping task involving dynamic content, JavaScript offers a robust and flexible solution.
However, as far as this guide is concerned, we'll perform web scraping in Javascript using Puppeteer. Let's walk you through the step-by-step process of how to do web scraping using Javascript with Puppeteer.
How To Do Web Scraping Using Javascript Puppeteer?
Web scraping can sometimes feel daunting, but the task becomes 10x easier if you know the right tools. In this section, we'll explore how to use Puppeteer, a Node library, for web scraping. Puppeteer is a perfect Javascript tool for scraping dynamic content.
Let's break down the process into three simple steps, showing you how to scrape images from a Google search for "happy dog". Let's dive in!
Step 1: Making a New Directory and Installing Puppeteer
First things first, let's set up our project environment. First, create a new project directory and initialize it.
Then, install Puppeteer, which we will be using for scraping. Open your console and execute the following commands:
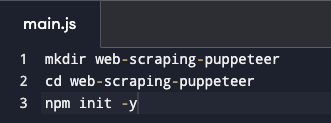
-
For creating a new directory: mkdir web-scraping-puppeteer
-
For moving into the directory: cd web-scraping-puppeteer
-
Initializing a new Node.js project: npm init -y
-
Installing Puppeteer: npm install puppeteer
Step 2: Writing the Initial Code
Now, let's write the initial code to launch a browser, navigate to Google Images, and search for "happy dog". We will use Puppeteer to open a new browser window, set the viewport, and interact with the page elements.
Here's the code for this step: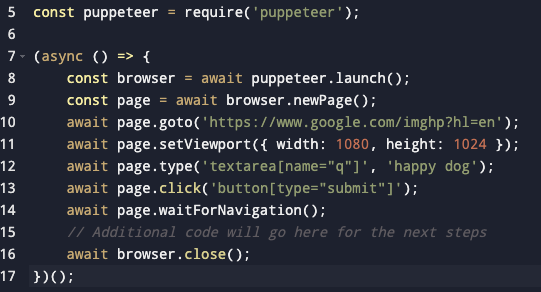
Explanation of The Code:
-
const puppeteer = require('puppeteer');
-
Remember in the first step we installed the Puppeteer in our system? Well, this line imports the Puppeteer library into the script. It then allows us to use its functionalities to control a headless browser.
-
-
(async () => { ... })();
-
This line will declare an asynchronous function. This function will handle the web scraping tasks. Asynchronous functions allow us to wait for certain actions to complete (like page loads) before moving on to the next step, which is crucial in web scraping.
-
-
const browser = await puppeteer.launch();
-
This line tells Puppeteer to start a new browser session. The await keyword is used to ensure that the browser is fully launched before the script proceeds.
-
-
const page = await browser.newPage();
-
After launching the browser, this command opens a new page (or tab) in the browser.
-
-
await page.goto('https://www.google.com/imghp?hl=en');
-
The script navigates the opened page to the specified URL, which is the Google Images search page in this case. The await keyword ensures the navigation is complete before proceeding.
-
-
await page.setViewport({ width: 1080, height: 1024 });
-
This sets the dimensions of the viewport (the viewable section of the page). It's important for screenshots or for pages that change layout based on screen size.
-
-
await page.type('textarea[name="q"]', 'happy dog');
-
This command simulates typing the text 'happy dog' into an input field on the page, specifically a text with the name attribute 'q' (which, in Google Images, is the search field).
-
-
await page.click('button[type="submit"]');
-
This line simulates a click on the submit button of the form, triggering the search.
-
-
await page.waitForNavigation();
-
After clicking the submit button, this command waits for the page navigation to complete (i.e., waits for the search results to load).
-
-
await browser.close();
-
Once all the previous steps are completed, this command closes the browser.
-
Step 3: Fetching the Image of the "happy dog" from Google Images.
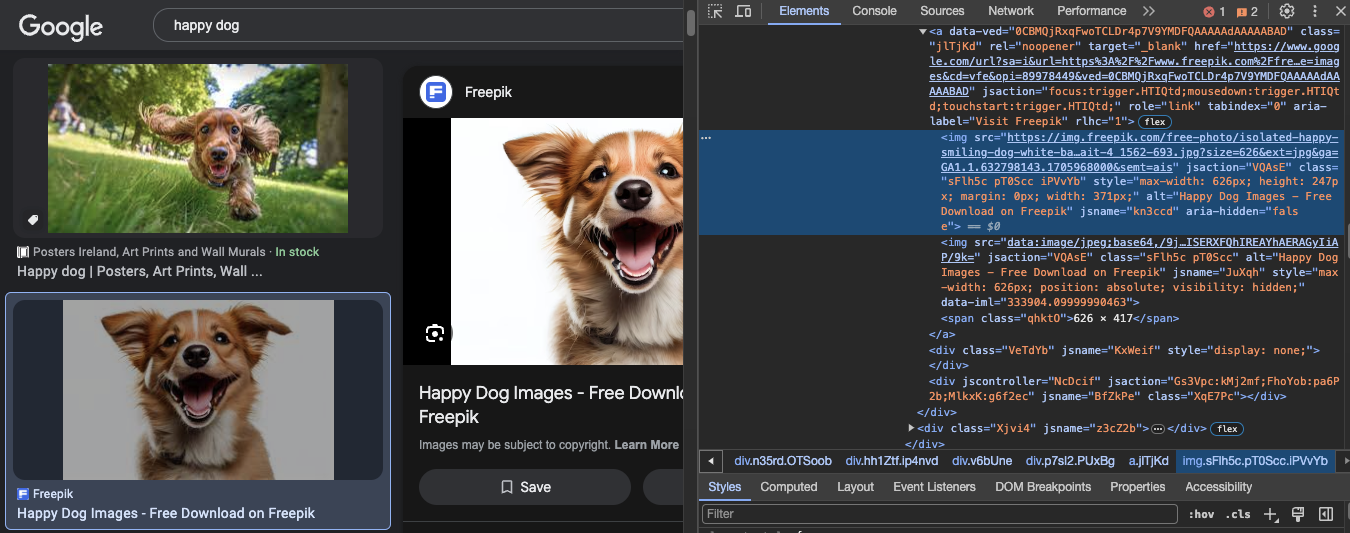
Now our goal is to select the image we want to scrape and identify its class, ID, and source URL, inside its div.
To do that, you need to open your browser, search for "happy dog", and click on the image you want to scrape. After the image is expanded, right-click on it and select the "Inspect" option.
Inspect option will show you the div container of the image which will have its class, ID, and source URL that you need to copy to include in our code.
Here's what the full code would look like:
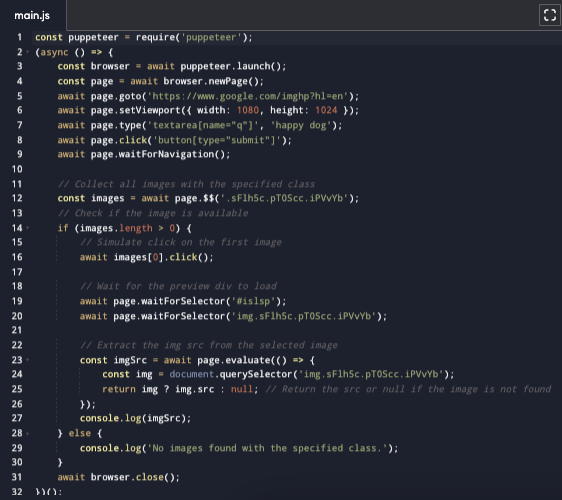
In this code:
-
We first ensure that Puppeteer navigates to Google Images and performs the search for "happy dog".
-
Once the results are loaded, we select all images that match the class '.sFlh5c.pT0Scc.iPVvYb'.
-
We then click on the desired image in the list to trigger the preview.
-
We wait for the preview container (#islsp) and the large image inside it to load.
-
Finally, we extract the src attribute of the large image, which contains its URL.
In case you’re wondering, we used “if” and “else” statements in this code to ensure that it returns “No images found with the specified class” in case of the wrong class. Otherwise, sometimes, code breaks.
You have now successfully learned how to scrape a website using Javascript and Puppeteer. You can use the same approach to scrape multiple images from any website.
However, some websites do not allow you to scrape their content. They have anti-scraping techniques in place that make it hard for you to get the job done. Or even worse, you may end up getting blocked altogether.
But there’s a solution to this problem as well. Head to the next section to learn more about how you can scrape websites without getting detected or blocked.
Use AdsPower for Undetected Browsing
If you want to add a layer of protection while data scraping using JavaScript, AdsPower is the best anti-detect browser you can use. AdsPower browser ensures a seamless web scraping experience by effectively dodging anti-scraping challenges.
You can also use it to create multiple user profiles and remain anonymous on the web. Sign up today to secure your tomorrow.
Wrapping Up!
Learning how to do web scraping using JavaScript opens up a world of data possibilities. Whether it’s for personal projects or professional analysis, tools like Puppeteer make it accessible and efficient.
Use the technique mentioned in this blog and scrape the information you need. Also, don't forget to use AdsPower for safe scraping.
İnsanlar Ayrıca Okuyun
