
5 эффективных способов парсить веб-страницы без риска блокировок

Вы знали, что примерно 47% всего интернет-трафика генерируется ботами, включая парсеры? В цифровом мире, где данные играют важнейшую роль, парсинг веб-сайтов стал необходимостью для многих компаний.
Однако, несмотря на важность этого процесса, он связан с определенными трудностями, начиная от CAPTCHA, которые блокируют автоматизированный доступ, и заканчивая ловушками антифрода, которые привлекают и разоблачают ботов.
Однако основная цель — не в этих преградах. Мы здесь, чтобы рассказать эффективные решения для обхода этих ограничений и обеспечить стабильный парсинг сайтов без блокировок.
Эта статья рассказывает 5 способов успешного парсинга без риска блокировок. Мы рассмотрим широкий спектр способов, начиная с использования сложного антидетект браузера и заканчивая планированием задач парсинга.
Применяя эти методы, вы не только снизите вероятность блокировок, но также повысите эффективность сбора данных.
Проблемы парсинга веб-страниц
Риски и проблемы, связанные со сбором данных, варьируются от технических барьеров до преднамеренной установки ловушек на страницах сайта. Понимание этих проблем является ключевым моментом в разработке надежной стратегии парсинга.
Ниже мы выделяем несколько наиболее распространенных проблем, с которыми сталкиваются специалисты парсинга.
5 способов парсинга веб-страниц без риска блокировки

Хотя при парсинге данных существует множество проблем, для каждой есть решения, как их обойти. Давайте рассмотрим эти методы и попытаемся запомнить, как они могут облегчить парсинг веб-страниц и защитится от блокировок.
Headless режим браузера
Один из способов осуществлять парсинг веб-страниц без блокировок - это техника, называемая headless web scraping. Этот подход заключается в использовании браузера без графического интерфейса пользователя (GUI). Headless режим браузера может имитировать типичную активность пользователя в Интернете, помогая оставаться незамеченным на сайтах, использующих Javascript для отслеживания и блокировки парсеров.
Эти браузеры особенно полезны, если целевой сайт загружен элементами Javascript, поскольку традиционные HTML парсеры не способны корректно обрабатывать такие страницы, как настоящий пользователь.
Основные браузеры, такие как Chrome и Firefox, поддерживают такой режим, но вам все равно придется настроить их поведение, чтобы они казались аутентичными. Кроме того, можно добавить еще один уровень защиты, комбинируя headless режим браузера вместе с прокси, чтобы скрыть свой IP-адрес и еще сильнее уменьшить риск блокировки.
Вы можете управлять headless Chrome программно, через Puppeteer, предоставляющий продвинутый API для просмотра страниц сайтов и выполнения практически любых действий на них.
Вот пример простого сценария кода в Puppeteer для посещения сайта и создания скриншота на нем, а также закрытия окна после выполненных действий:
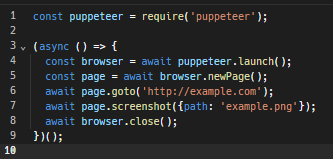
Вот подробная инструкция использования режима headless с помощью Puppeteer.
Парсинг во время низкой активности
Парсинг данных заключается в просмотре страниц очень быстрым темпом, что нетипично для обычных пользователей. Это может привести к высокой нагрузке на сервер и замедлению обслуживания других пользователей. В результате администраторы веб-сайтов могут обнаружить ваш парсер и исключить его с сервера.
Поэтому умным решением для использования веб-парсинга является выполнение операций во время низкой активности на сайте. Обычно в это время сайты находятся в менее настороженном состоянии. И даже если ваши операции сбора данных потребляют много серверных ресурсов, этого скорее всего, будет недостаточно для исчерпания ресурсов сервера и следственно привлечения внимания администраторов.
Однако все равно существует риск быть обнаруженным. Некоторые сайты могут использовать сложные системы для мониторинга пользовательской активности даже в период низкой посещаемости. Стоит помнить это и всегда быть крайне осторожным.
Использование антидетект браузера
Антидетект браузер - это комплексный инструмент, разработанный для обеспечения анонимности пользователей и скрытия их онлайн-активности от посещаемых ими веб-сайтов. Он работает путем маскировки или изменения цифрового отпечатка пользователя, который обычно состоит из таких параметров, как тип и язык браузера, расширения, разрешение экрана, часовой пояс, и многих других. Все эти параметры помогают сайтам идентифицировать вас.
Это делает антидетект браузеры идеальными помощниками для веб-парсинга. Однако важно отметить, что эти браузеры только уменьшают риски обнаружения; они не являются полностью анонимными перед всеми веб-сайтами. Поэтому выбор лучшего антидетект браузера для работы является ключевым моментом для минимизации рисков блокировок.
Действительно надежный антидетект браузер для парсинга - это AdsPower. Он использует следующие специфические техники для обхода антифрод систем:
Помимо этих функций, AdsPower также предлагает дополнительные преимущества, это как автоматизация парсинга и множество профилей браузера для ускорения процесса сбора данных.
Автоматизируйте решение CAPTCHA или используйте дополнительные платные услуги
Решить CAPTCHA при веб-парсинге без блокировки можно несколькими способами. Во-первых, рассмотрите возможность получения необходимой информации без доступа к защищенным CAPTCHA разделам, так как написание прямого решения сложный процесс.
Однако, если доступ к этим разделам критично важен, вы можете использовать дополнительные услуги для решения CAPTCHA. Например сервисы 2Captcha и Anti Captcha, нанимают реальных людей для решения CAPTCHA с оплатой за каждый решенный тест. Но помните, что полная зависимость от этих услуг может ударить по вашему кошельку.
В качестве альтернативы, специализированные инструменты для веб-парсинга, такие как ZenRows' D и инструмент для сбора данных от Oxylabs, могут автоматически обходить CAPTCHA. Эти инструменты используют передовые алгоритмы машинного обучения для, чтобы обеспечить беспроблемную работу ваших парсинг-активностей.
Honeypot Traps или ловушки-приманки
Чтобы эффективно справиться с ловушками типа “honeypot traps” при веб-парсинге, важно уметь их распознавать и избегать. Ловушки типа "honeypot traps” представляют собой механизмы, задуманные для приманивания и идентификации ботов, часто представленные как невидимые ссылки в HTML-коде сайта, скрытые от пользователей, но видны для парсеров.
Одна из стратегий - это программировать свой парсер или краулер для идентификации ссылок, которые делаются невидимыми для человека с помощью CSS-свойств. Например, избегайте перехода по текстовым ссылкам, сливающимся с фоновым цветом, так как это тактика для умышленного скрытия ссылок от человеческих глаз.
Вот простая JavaScript-функция для обнаружения таких невидимых ссылок:
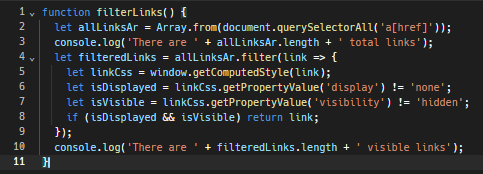
Кроме того, важно помнить про файл robots.txt сайта. Этот файл предназначен для ботов и содержит в себе правила обязательные и запрещенные для сканирования ботами. Он предоставляет информацию об участках сайта, к которым доступ ограничен, и местах, где сканирование разрешено. Соблюдение этих правил – это хорошая практика, которая может избежать вышеописанных ловушек.
Подведение итогов!
Конечно же, меры защиты от парсинга существуют, они мешают нам получать доступ к ценным данным на целевых веб-сайтах и иногда могут привести к постоянной блокировке доступа. Но ни одна из этих мер не является непреодолимой.
Вы можете использовать эффективные инструменты, такие как браузер в режиме headless, чтобы имитировать реальное поведение пользователя интернета, собирать данные в менее загруженное время, а также использовать антидетект браузеры, например AdsPower, чтобы скрыть вашу цифровую личность. Более того, существуют даже способы обойти CAPTCHA и избежать хитрых ловушек.
С использованием этих тактик, шансы на успешных парсинг, без блокировок, значительно увеличиваются. Итак, давайте же применять эти советы и начнем парсить по-умному.

Люди также читают
- Что такое нейросеть и как заработать на нейросетях в 2025 году
- Как заработать на Spotify? Вот как люди получают прибыль
- Антидетект браузер партнерских маркетологов: избегайте блокировок и увеличивайте ROI
- Партнерская бизнес модель: 8 ключевых типов для вашего бизнеса (Руководство на 2025 года)
- Амазон партнерская программа в России: как начать и монетизировать свой сайт
